3D-Rekonstruktionen von Objekten aus Schleiftomographie
Software-Praktikum für Fortgeschrittene von Sarah Fenrich und Marian Röhling unter Aufsicht und Betreuung durch Dr. Susanne Krömker in Zusammenarbeit mit Dr. Christina Ifrim.Einführung
In Zusammenarbeit mit den Geowissenschaftlern entwickelte sich eine interessante Aufgabenstellung im Bereich der 3D Rekonstruktion. Im Institut der Geowissenschaften, wird Schleiftomographie genutzt, um versteinerte Fossilien zu untersuchen. Während des Vorgangs der Schleiftomographie entstehen viele Querschnitte, die im Nachgang zu einem 3D Modell rekonstruiert werden sollen. Ziel des Praktikums ist es, einen Workflow zu entwickeln, welcher 3D Modelle aus den Schnittbildern rekonstruiert.
Schleiftomographie

Schleiftomographie ist eine computergestützte Methode zur dreidimensionalen Analyse der Morphologie von Fossilien, aber auch anderer Objekte. Übereinander liegende parallele Anschliffe werden fotografiert und diese Scans über den Rechner zu einem dreidimensionalen Modell zusammengesetzt. Obwohl dabei das Fossil selbst zerstört wird, bleibt es virtuell erhalten und kann dann auch als virtuelles Objekt in Sammlungen inventarisiert werden. Der durch die Schleiftomographie gewonnene Datensatz erlaubt wesentlich detailliertere Einblicke in die innere Morphologie des Objektes als bisher möglich.[1]
Aufbau der Fossilien
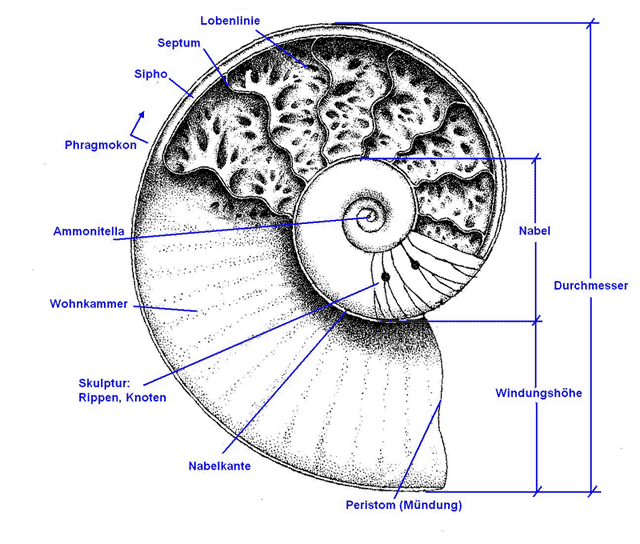
Bild: mineralienatlas.de

Bild: mineralienatlas.de
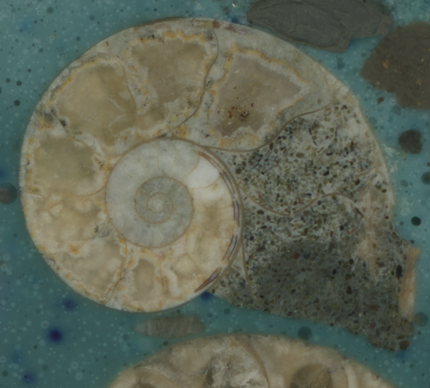
Die von uns untersuchten Datensätze zeigen komplett versteinerte Cephalopoda (Kopffüßer). Der Aufbau dieser Organismen setzt sich aus spiralförmig angeordneten Kammern zusammen. Diese werden von den Septen voneinander räumlich getrennt. Sie sind lediglich durch eine einzelne Röhre (Sipho) miteinander verbunden. Da die uns vorliegenden Exemplare vollständig mit Zementen gefüllt sind, ist ein weiterer Arbeitsschritt notwendig. Dieser besteht darin, sämtliche Zemente herauszufiltern.
Datensätze

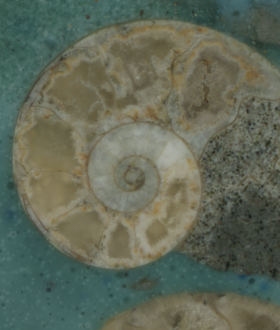
Ein Datensatz umfasst 300 bis 500 Bilder und hat eine gesamte Dateigröße zwischen 800MByte und 2,3GByte. Insgesamt standen drei Datensätze zur Verfügung. Die Auflösung der Bilder reicht von 600x700 bis 1400x1600 Pixel. Bei diesen Datengrößen ist es notwendig auf die Komplexität der eingesetzten Verfahren zu achten, da der Workflow auf einem Notebook/Desktopcomputer mit bis zu 16GByte Hauptspeicher ausgeführt werden soll.
(Fern) Ziel

https://www.volumegraphics.com
Ziel ist es, das zerstörte Objekt als 3D-Modell zu rekonstruieren und somit zu ermöglichen, dass man ins Innere des Objekts schauen kann, um die Erkenntnisse aus der Morphologie zu ziehen. Im Idealfall entsteht ein Modell, bei dem das Sediment gefiltert wurde und nur noch die Schale mit allen Kammern und die inneren Strukturen erhalten bleiben, d.h. ein Skelett anstelle eines soliden Blocks.
ilastik
ilastik ist ein interaktives Bildklassifizerungs-, Segmentierungs- und Analyseprogramm. Teil des Praktikums ist es, die Eignung von ilastik für die Rekonstruktion der Fossilien und Filterung der Zemente zu evaluieren. Dazu wurden die Workflows Pixel Classification und Carving von ilastik untersucht.
Segmentierung
Bevor das 3D-Modell rekonstruiert werden kann, muss zunächst das Objekt von der Matrix und den Zementen getrennt werden. Dazu werden verschiedene Ansätze ausprobiert, um die Datensätze erfolgreich zu segmentieren. Diese beinhalten unter anderem 'K-Means Clustering', 'Foreground Extraction' (Edge Detection), Watershed Algorithmus und das Filtern durch Farbeigenschaften.
Segmentierung über ilastik
In Ilastik existieren verschiedene Workflows. Für die Segmentation spielt insbesondere die 'pixel classification' eine wichtige Hauptrolle. Hier lassen sich im Vorprozess verschiedene Features auswählen, die dabei helfen sollen eine passende 'boundary map' zu erstellen. Im Bereich des Trainings findet schließlich die eigentliche Segmentation statt. Über die verschiedenen Label lassen sich Hintergrund (blau) und Objekt (gelb) auf dem Bild unterscheiden.


Probleme
Es werden zuviele Stellen als Objekt markiert und zudem nicht perfekt auf den kompletten Datensatz übertragen. Somit entstehen unsaubere Ergebnisse. Die Oberflächen weisen Artefakte und Löcher auf. Dies lässt sich durch händisches Labeling weiter verbessern, allerdings ist das bei 500 Bildern sehr zeitaufwändig und die Ergebnisse letzten Endes nicht gut genug. Der segmentierte Datensatz muss trotzdem noch bearbeitet werden, da mit Carving nur Graustufen Bilder bearbeitet werden können und das Bild eventuell herunterskaliert werden muss, um die Rechenzeit zu verringern.
Segmentierung über Photoshop
Hierbei geht es darum, das Objekt über händische Vorgehensweise auszuschneiden und dadurch die Segmentation über Ilastik zu vereinfachen und zu verbessern. Das Labeling von Vorder- und Hintergrund entfällt damit.
 Politissimum
Politissimum

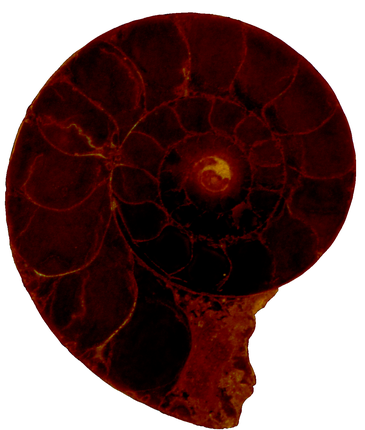
Probleme
Die Bearbeitung ist allerdings sehr Zeit aufwändig und die Ergebnisse je nach Sorgfältigkeit des Bearbeiters eventuell sehr kantig oder zu ungenau. Zusätzlich können durch ein falsch entstehendes Format Fehler auftreten, die den nachfolgenden Ablauf erschweren.
Segmentierung über 'Foreground Extraction'
Vorgehensweise
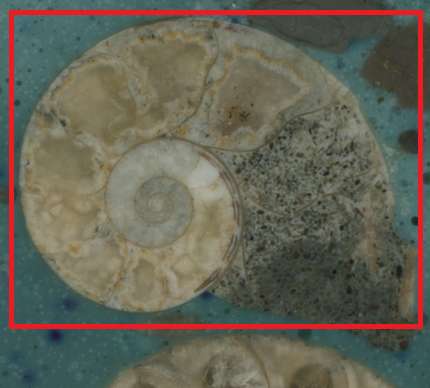
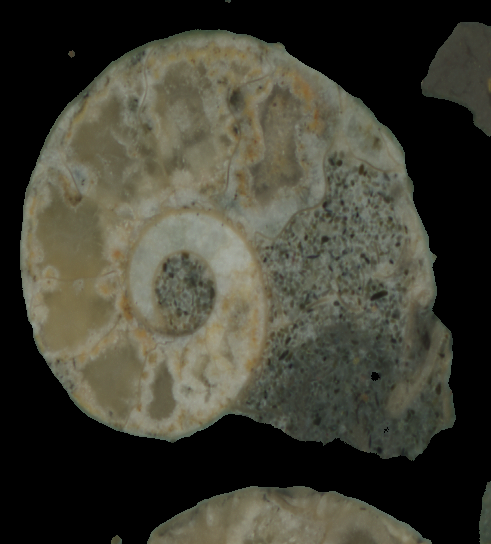
Die Foreground Extraction wird mit Hilfe des GrabCut Algorithmus umgesetzt. Zuerst wird ein Rechteck festgelegt, welches das im Vordergrund liegende Objekt komplett umschließen soll. Alles außerhalb des Bereichs wird sofort als Hintergrund erkannt. Bei der Ausführung des Codes werden als Input Daten hart gelabelte Vorder- und Hintergrund Informationen mitgegeben, diese ändern sich bis zum Ende des Prozess nicht. Die unbekannten Pixel werden an Hand von der farblichen Ähnlichkeit und Wahrscheinlichkeitsberechnungen zu den hart gelabelten Pixeln dem Vorder- oder Hintergrund zugeordnet (genauso wie beim Clustering).
Die Pixelverteilung wird als Graph dargestellt. Es werden zwei Knoten hinzugefügt 'Source node' und 'Sink node'. Jeder Vordergrund-Pixel wird mit dem 'Source node' und jeder Hintergrund-Pixel mit dem 'Sink node' verbunden. Die Kantengewichte zwischen den Pixeln und 'Source/ Sink node' werden abhängig von der Wahrscheinlichkeit als Vorder-/Hintergrund Pixel bestimmt und definieren somit die Pixel-Ähnlichkeit. Eine große Differenz in der Pixel-Farbe bedeutet, dass die Kante ein niedriges Gewicht erhält. Abschließend wird ein Mincut-Algorithmus für die Segmentierung des Graphs angewendet. Der Graph wird in zwei Teile geschnitten mit getrennten 'Source node', 'Sink node' und mit minimaler Kostenfunktion. Die Kostenfunktion ist die Summe aller Kantengewichte, die geschnitten werden. Nach dem Vorgang können weitere Pixel als Hintergrund festgehalten werden.[3]
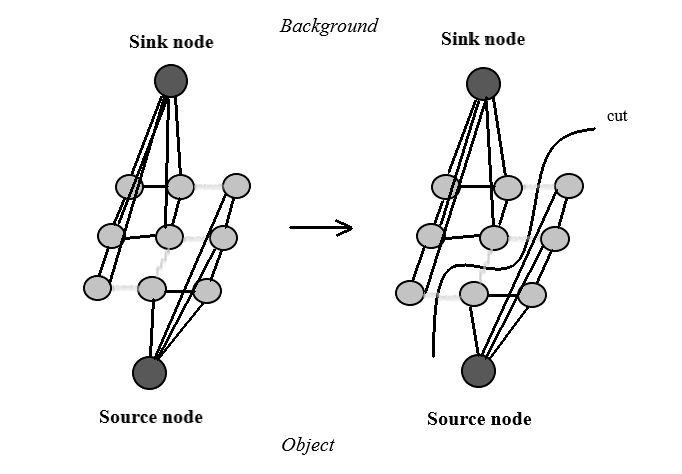
Der Prozess wird solange wiederholt bis die Klassifikation konvergiert. Durch den iterativen Vorgang möchte man das bestmögliche Ergebnis erzielen. Nachfolgend sieht man Beispiele für die Anwendung auf die Fossile.
 Politissimum
Politissimum
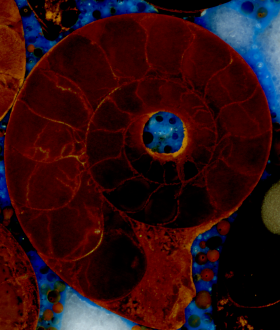
 Surya
Surya

Der GrabCut Algorithmus bietet zusätzlich eine Erweiterung über eine Schablone an. Dabei werden Objekt und Hintergrund mit Pinsel-Strichen markiert. Dies verfeinert und verbessert den Prozess, müsste aber für jedes Bild einzeln durchgeführt werden. Aus diesem Grund wurde hiermit innerhalb des Praktikums nicht mehr weitergearbeitet.
Probleme
Die Segmentierung ohne zusätzlicher Schablone ist in den meisten Fällen nicht genau genug, da sich die Maße für das Rechteck nicht exakt bestimmen lassen. Dabei verschwindet hin und wieder ein Teil des Objekts oder ein Teil des Hintergrunds wird als Objekt erkannt. Ein weiterer großer Nachteil besteht darin, dass die Maßangaben des Rechtecks nicht auf alle Datensätze gleichermaßen übertragen werden können. Es sind also zu viele Anpassungen notwendig. Selbst innerhalb eines Datensatzes verändert sich die Größe des Objekts auf den einzelnen Bildern. Somit müsste der Code für jedes Bild angepasst werden. Ein weiterer Punkt, der dagegen spricht, ist die Verwendung zuviel verschiedener Programme, vor allem wenn man beschließt mit einer Schablone zu arbeiten. Die Segmentierung mit Hilfe einer Schablone erfordert zusätzliche Programme, wie Paint oder Photoshop zum Beispiel. Alle weiteren Bearbeitungen, wie die Reduzierung der Farbkanäle oder Skalierung des Bildes, würde man mit Python durchführen. Insgesamt ist diese Technik sehr zeitaufwändig und kommt also nicht in Frage.
Segmentierung über k-Means
Da sich die Farben des Vorder- und Hintergrundes stark unterscheiden, ist k-Means Clustering eine Segmentierungsmethode, welche sich für unsere Datensätze eignet. In den folgenden Abbildungen ist gut zu erkennen, wie sich der Hintergrund für verschiedene k vom Vordergrund trennt.
 k=2
k=2
 k=3
k=3
 k=5
k=5
Bei genauerer Betrachtung des bearbeiteten Datensatzes mussten wir jedoch feststellen, dass sich Artefakte gebildet haben, die das Ergebnis der 3D-Rekonstruktion verschlechtert haben. Vor allem an den Rändern des Bilderstapels wurden Teile des Fossils vom Cluster verschluckt, da dort die Querschnitte des Fossils sehr klein und somit nicht mehr relevant für einen Cluster waren. An anderen Stellen in den Fossilien sind Löcher entstanden.
Ohne weitere, manuelle Bearbeitung und Überprüfung auf Richtigkeit der Ergebnisse ist diese Methode für unser Ziel ungeeignet.
Segmentierung über HSV-Farbraum
 Surya
Surya
 Surya
Surya
 Surya
Surya
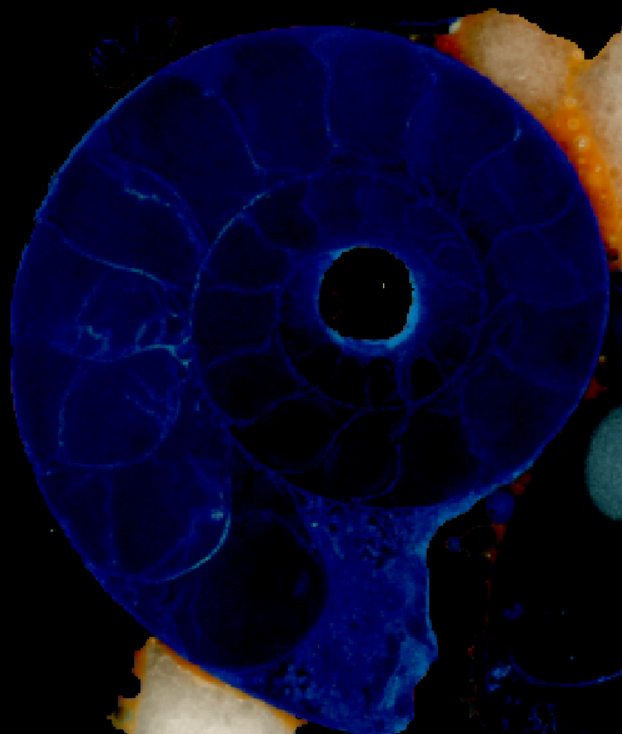
Bei der Analyse der Datensätze fällt schnell auf, dass das Kunstharz, in dem die Fossilien eingebettet sind, blau eingefärbt ist. Daher ist es möglich das Bild nach Farben zu labeln. Im Kunstharz befinden sich eingeschlossene Luftblasen, welche beim einscannen Schatten werfen und Licht reflektieren. Dadurch entstehen helle und dunkle Flecken im Bild. Wir haben uns daher für eine Filterung über den HSV-Farbraum entschieden, da die Schatten und Reflektionen zwar den Wert Farbe und die Sättigung beeinflussen, weniger aber den Farbton. Dies ermöglicht uns einen globalen Schwellenwert zu nutzen, der auf dem gesamten Bilderstapel angewendet wird.
Zusätzlich wird das Bild geglättet, um das Rauschen zu minimieren. Ausreißende Pixel, die sich stark von ihren Nachbarpixeln unterscheiden werden so entfernt.
Mit dem Befehl python3 filterHSV.py --src "data/surya" --dest "results/surya" können wir nun einen Bilderstapel bearbeiten. Dabei wird ein Quellordner src ausgewählt und ein
Zielordner dest angegeben, in dem die zu verarbeitetenden Dateien gespeichert werden. Das Kunstharz ist
nun aus den Bildern entfernt und damit sind die Daten bereit für die 3D-Rekonstruktion.
3D-Rekonstruktion
Für die Rekonstruktion eines 3D Modells wird in Ilastik der Workflow des 'Carving' durchgearbeitet.
Carving in Ilastik
Der gesetzte Watershed Algorithmus wird für die Segmentierung von Bildern verwendet, welches interaktiv das Objekt aus dem Bild extrahiert. Als Input werden dem Algorithmus benutzer definierte farbliche Markierungen übergeben, z.B. für das Objekt grün und für den Hintergrund eines Objekts rot. Ausgehend von diesen Markierungen wird eine initiale Segmentierung berechnet, welche interaktiv verfeinert werden kann.
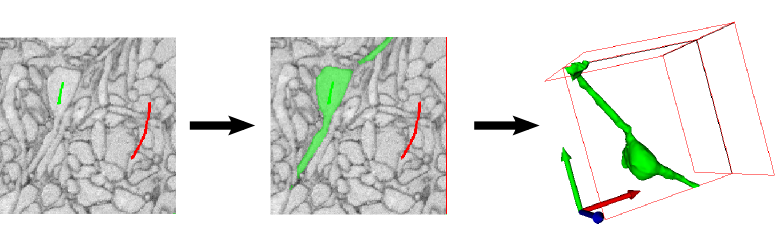
Bild: https://www.ilastik.org
Idee des Watershed Algorithmus
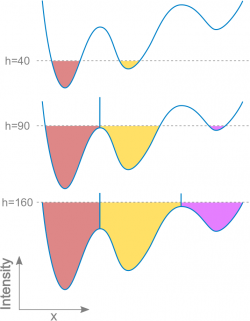 Bild:https://imagej.net/Classic_Watershed
Bild:https://imagej.net/Classic_Watershed
Watershed nimmt ein Grauwertbild entgegen und interpretiert dabei die Farbwerte als Höheninformation. Dadurch entsteht ein Grauwertgebirge, bei dem helle Pixel Bergspitze und dunkle Pixel Täler sind. Anschließend wird das Gebirge nach und nach geflutet, sodass Staubecken entstehen. Um das Zusammenfließen der einzelnen Staubecken zu vermeiden, werden diese mit Schranken abgegrenzt. Die einzelnen Staubecken bilden die Segmente des Bildes, welche anschließend durch das carving-tool in ilastik zusammengeführt werden.
Vorprozess in Carving[2]
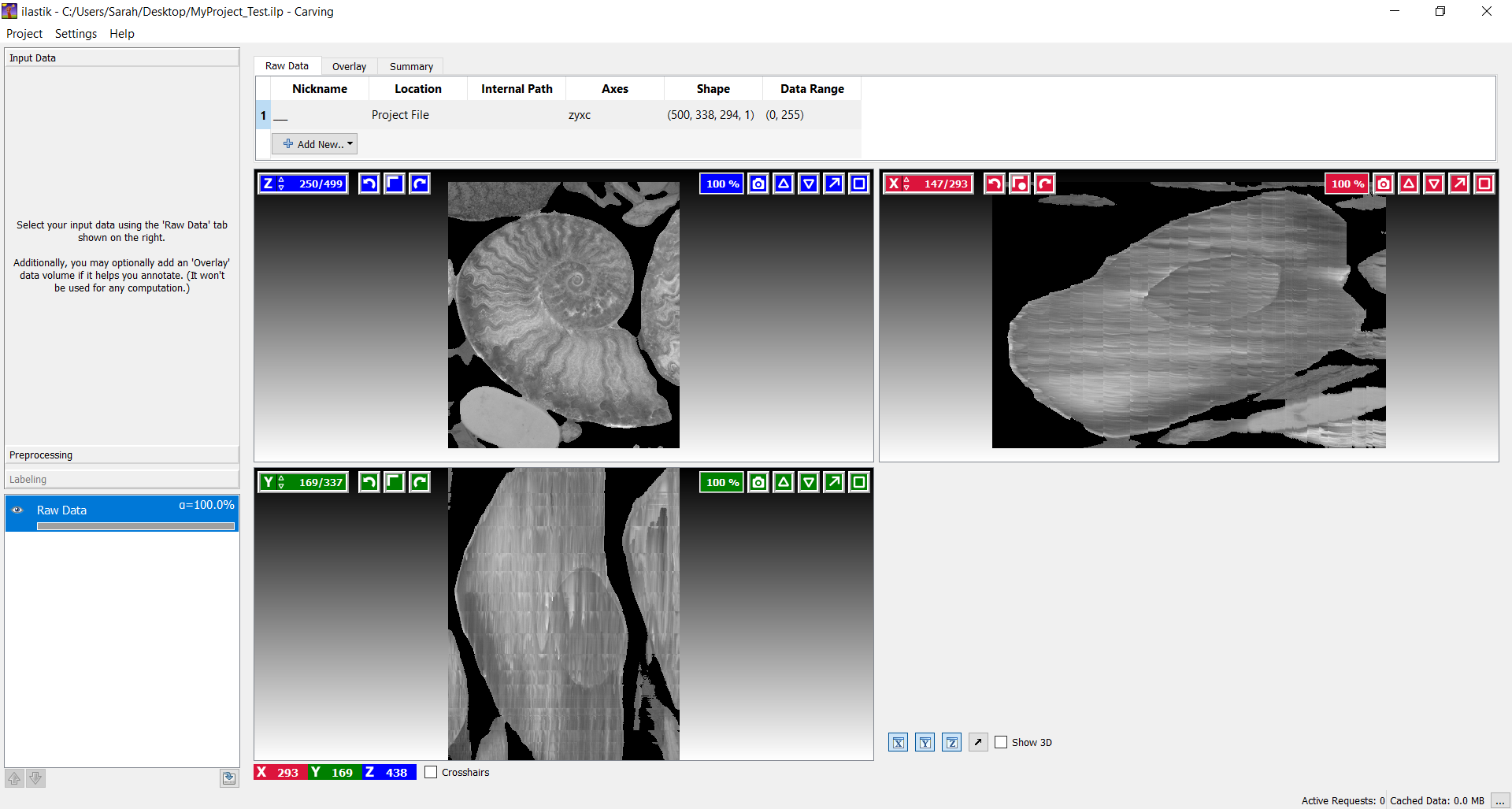
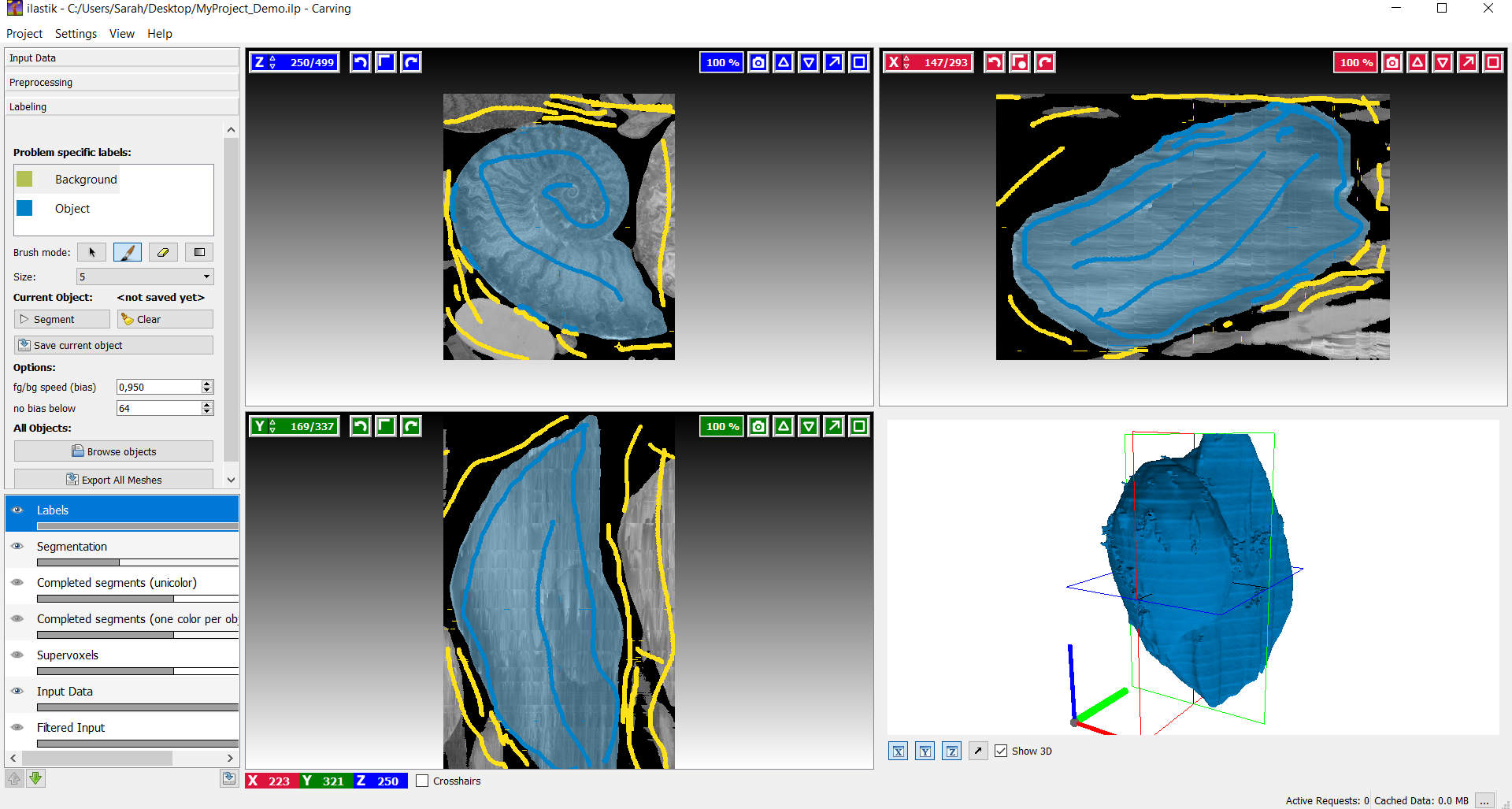
Über den ersten Abschnitt 'Input Data' kann ein Datensatz hinzugefügt werden. Notwendige Eigenschaften der Input Daten sind unter anderem, dass das Bild nur einen Farbkanal besitzt und dass das Bild angemessen skaliert wurde, um die Rechenleistung auf ein Minimum zu reduzieren. Nach dem Import des Datensatzes, werden die drei Hauptachsen (X, Y, Z) in einzelnen Ansichten dargestellt. Im unteren rechten Bereich des Arbeitsfensters wird während des Carving-Prozesses das 3D-Modell angezeigt. Um nun in den Vorprozess in Carving zu gelangen wechselt man einfach links zum nächsten Tab 'Preprocessing' des Workflows, dort gibt es eine Auswahl von Filtern, die für eine gelungene 'Boundary Map' entsprechende Berechnungen durchführen.
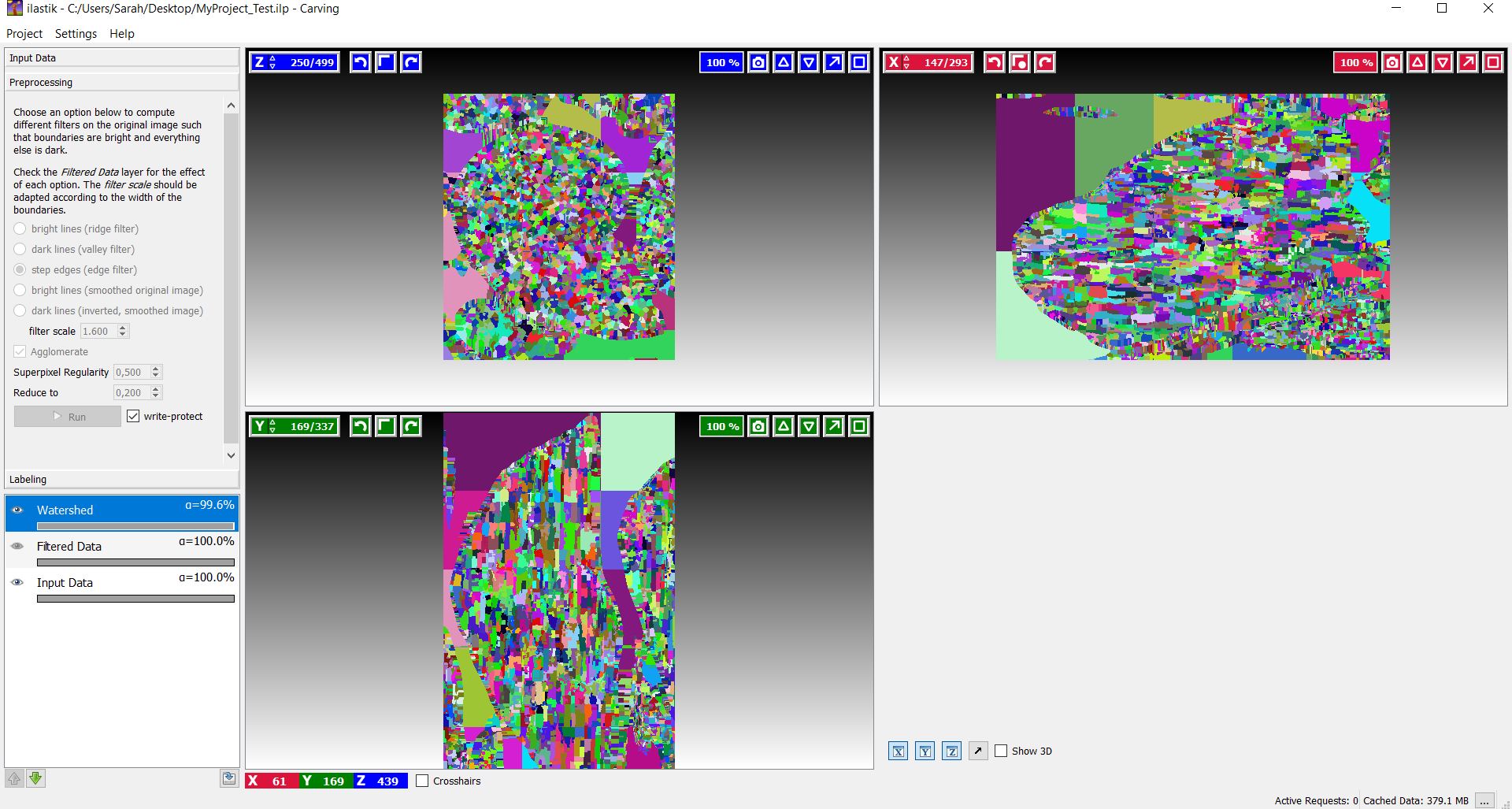
Der Benutzer kann nun auswählen, wie die Grenzen auf dem Bild repräsentiert werden sollen. Falls die Grenzen helle Pixel aufweisen, sollte 'Bright lines' benutzt werden und bei dunklen Pixel entsprechend 'Dark lines'. Manchmal treten aber wechselnde Übergänge von hellen und dunklen Regionen auf, hier sollte auf 'Step edges' zurückgegriffen werden, um eine saubere Trennung zu erhalten. Schließlich gibt es zu 'Bright lines' und 'Dark lines' jeweils noch eine erweiterte Form als 'smoothed image'. Diese werden benötigt, falls das geladene Bild bereits eine 'Boundary Map' aufweist.
In diesem Fall wäre 'step edges' eine gute 'Boundary'-Auswahl. Um zu prüfen, ob die berechneten Grenzen bildlich mit den Kanten auf dem Bild übereinstimmen, kann die Sichtbarkeit der einzelnen Ebenen über das Eye-Icon ein- und ausgeblendet werden.
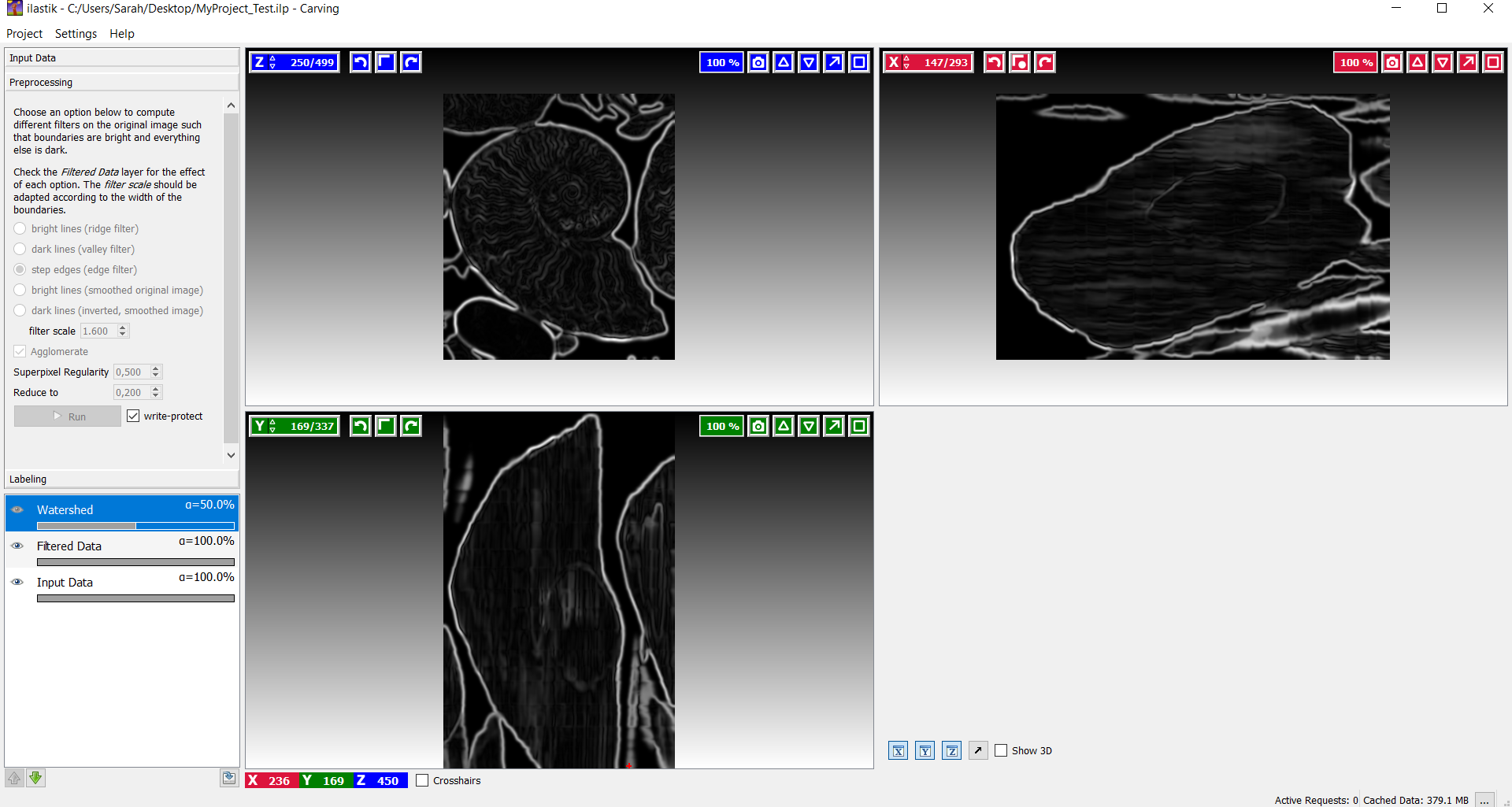
Falls die 'Boundary Map' nicht optimal erstellt wurde, kann man die Größe des Smoothing Kernels mit der Sigma Option anpassen. Diese Einstellung sollte allerdings solange bearbeitet werden, bis man eine zufriedenstellende Boundary Map erhält. Zur Überprüfung des Ergebnisses, sollte zwischendurch immer mal wieder der 'Run' Button betätigt werden. Die Daten werden zwar automatisch aktualisiert, aber die neuen Berechnungen muss man durchlaufen lassen. Dieser Vorgang wird die Zeit zum Segmentieren beschleunigen. Die Dauer des Vorprozesses ist abhängig von der Größe des Datensatzes und der Leistung des Computers. (Auf einen i7 2.4GHz Computer und einem 500×500×500 3D Datensatz benötigt der Vorgang 15 Minuten.)
Labeling[2]
Nach dem notwendigen Vorprozess ist das Labeling der nächste Schritt für eine interaktive Segmentation. Es existieren zwei unterschiedliche Typen von Markern. Einer markiert das Objekt und der Andere den Hintergrund. Über den Default Wert wird festgelegt, dass der Hintergrund-Marker eine höhere Priorität erhält. Das heißt im Fall uneindeutiger Grenzen wird der Hintergrund-Marker bevorzugt.
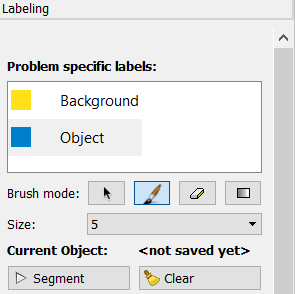
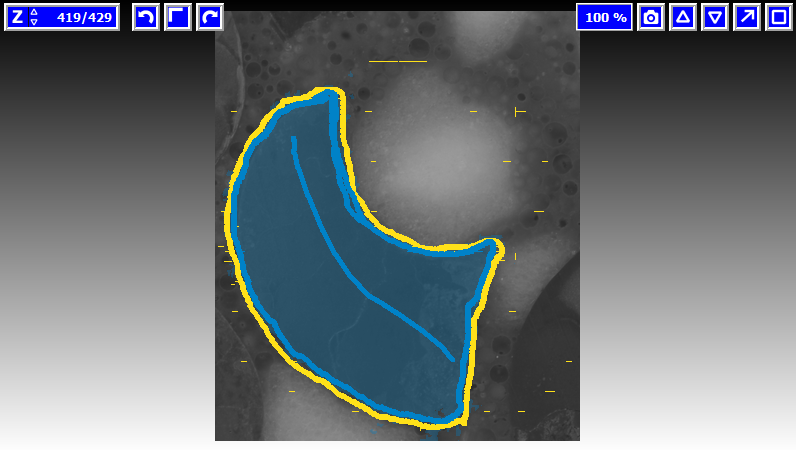
Nachdem die Stellen (Objekt/ Hintergrund) entsprechend markiert wurden, kann der Button 'segment' angeklickt werden, um den Prozess zu starten. Dabei wird die Segmentierung ausgehend von den Markierungen begonnen. Dieser Prozess wird als interaktiv bezeichnet, weil es einem die Möglichkeit bietet weitere Markierungen zu setzen, um die Segmentierung zu verfeinern. Links in der Spalte kann jederzeit der Marker getauscht werden. Auch falsch gesetzte Striche lassen sich wieder entfernen, dazu muss man zum Radiergummi Symbol wechseln. Um alle Zeichnungen auf einmal aufzuheben, gibt es schließlich noch den 'clear' Button. Über den rechten Mausklick lässt sich die Farbe des Markers ändern, dies spielt vor allem bei der Segmentierung eines Teilbereichs des Objekts eine wichtige Rolle.
Um die aktuelle Segmentierung zu exportieren, muss man einen Rechtsklick links unten auf der Layer-Liste durchführen und schließlich 'export' auswählen. Der Watershed Algorithmus hat einige Optionen, die geändert werden können, um eine verbesserte Segmentierung zu erhalten, wenn die 'Default' Einstellungen nicht ausreichend sind. Diese zusätzlichen Optionen findet man links in der Spalte beim hinunter Scrollen. 'Bias' ist ein Parameter, der angibt, wie sehr der Hintergrund im Vergleich zu den anderen Labeln vorgezogen wird. Der vorgegebene Wert von ungefähr 0.95 liefert normalerweise gute Ergebnisse. Manchmal ist es jedoch sinnvoll mit den Parametern zu spielen, um die Segmentierung ohne zusätzliche Markierungen zu verbessern. 'No bias below' ist ein Wert, der sich auswirkt, wenn die 'BG priority' (BG entspricht Background) für den Hintergrund eingesetzt wird. Nur bei ausreichend kräftigen Grenzen (z.B. >64) wird es als Hintergrund bevorzugt. In den meisten Fällen ist es nicht notwendig diesen Parameter zu ändern.
3D Objekt
Nachdem das Bild bezüglich Objekt und Hintergrund entsprechend markiert wurde, wird das 3D Modell berechnet und rechts unten im Kasten angezeigt. Man hat hinterher nun die Möglichkeit entweder das gleiche Bild weiterzubearbeiten oder innerhalb der verschiedenen Achsen die Bilder noch weiter durchzugehen und weitere Markierungen zu setzen, um das Ergebnis zu optimieren.
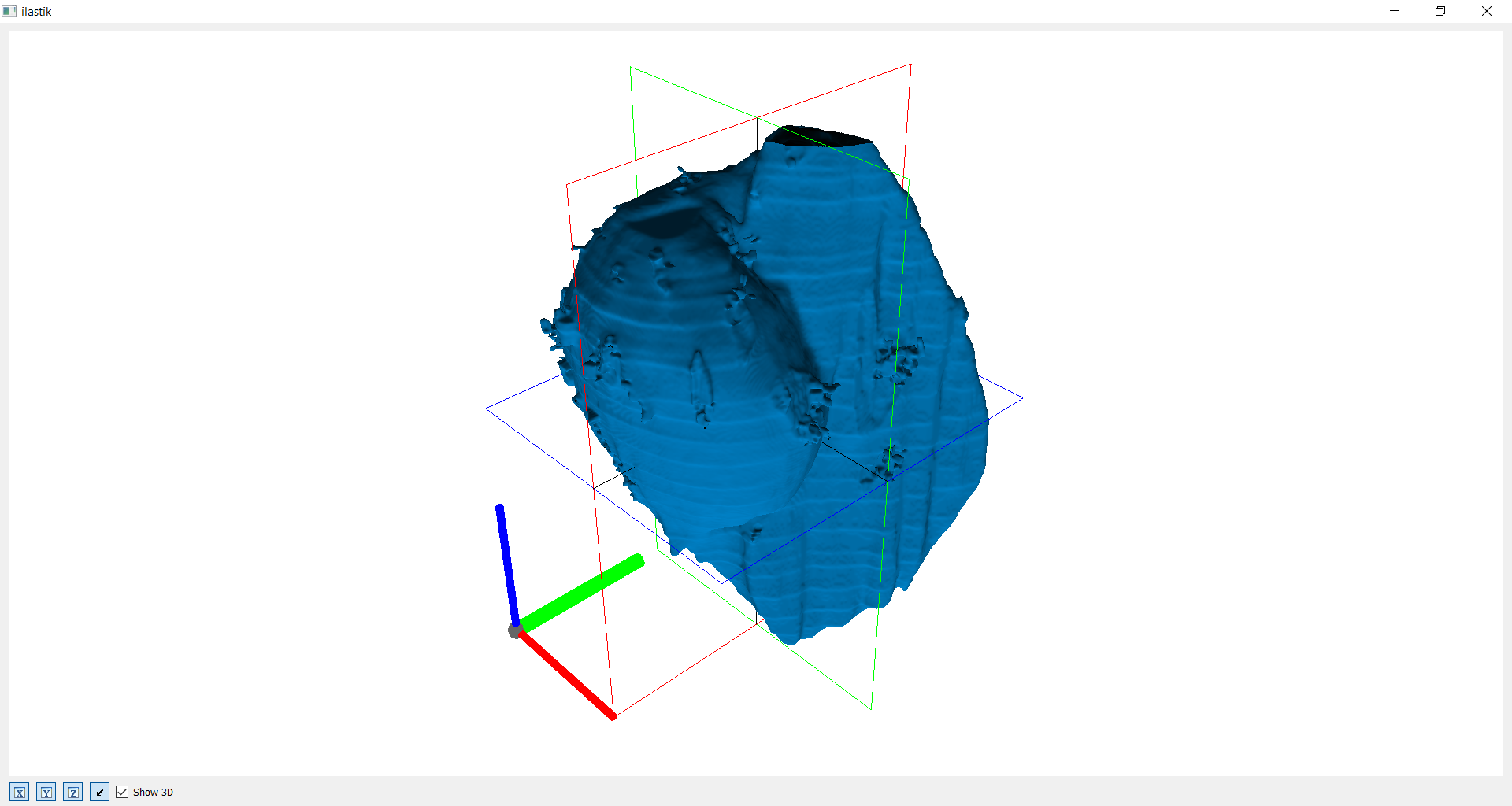
Ohne vorherige Bearbeitung
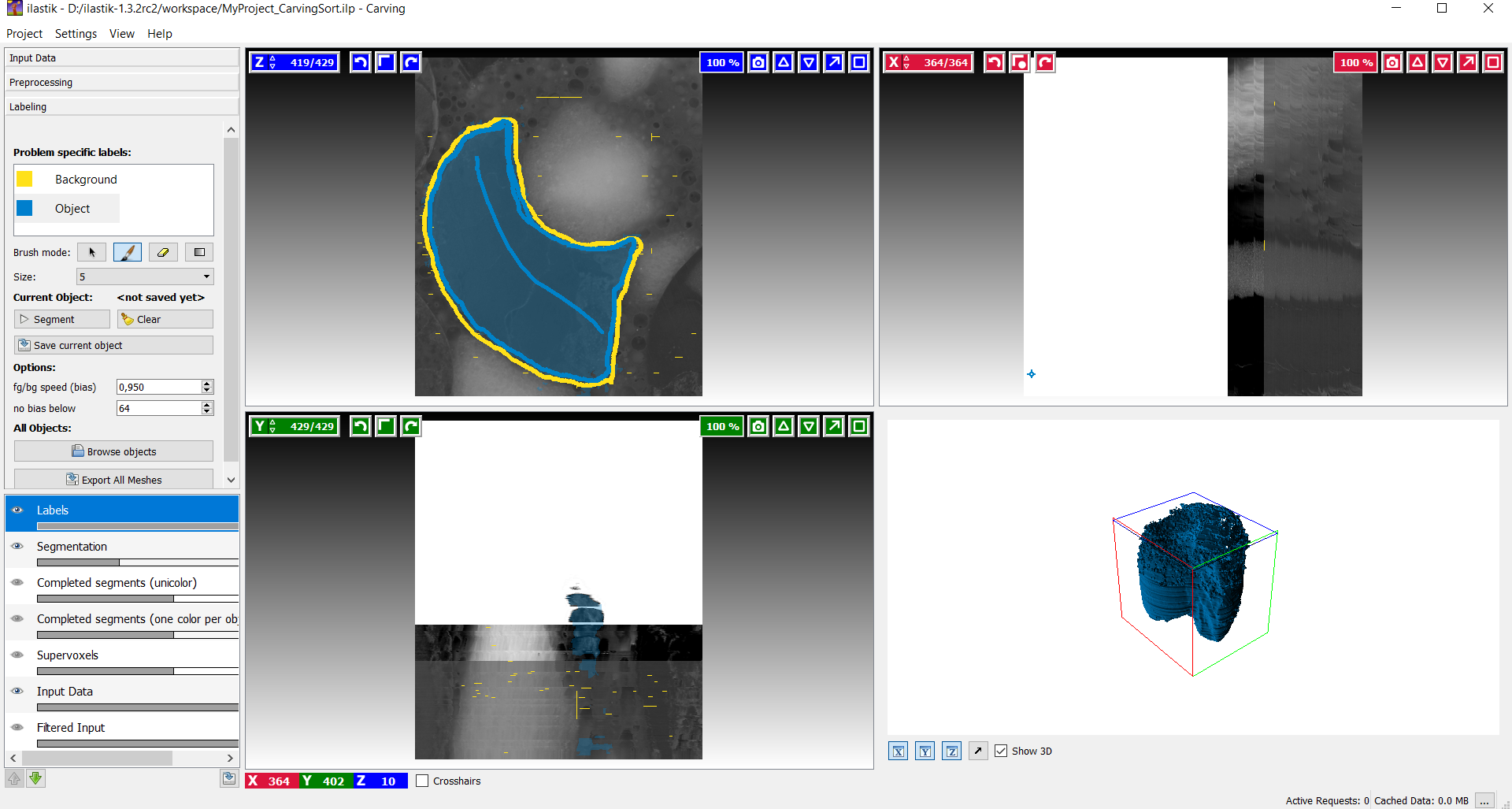
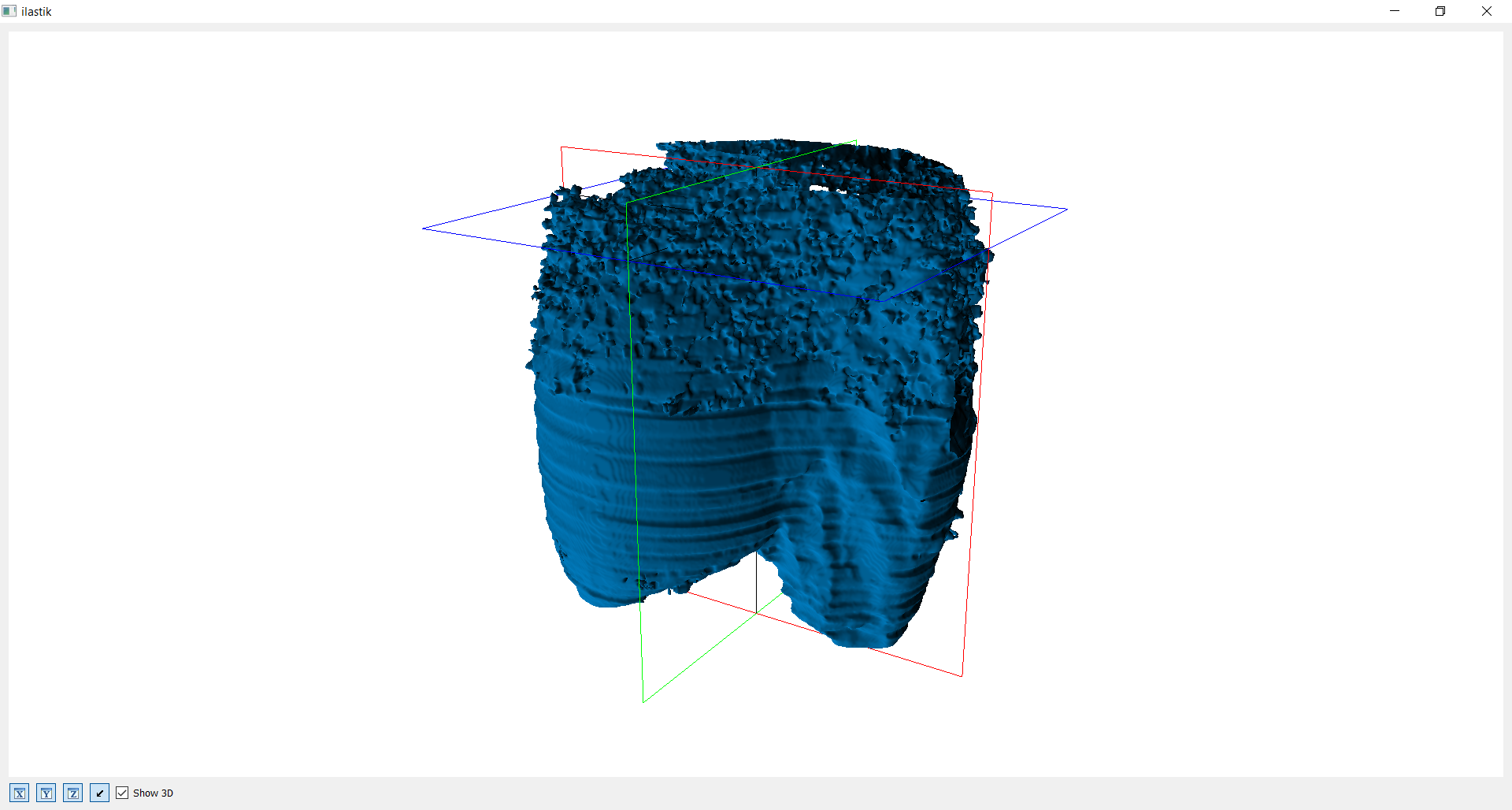


Auf diesen Bildern sieht man die erste Version eines 3D Modells. Der verwendete Datensatz wurde zur Häfte mit Photoshop bearbeitet. Dadurch lässt sich der Kontrast zwischen relativ glatter und unebener Oberfläche schön erkennen. Für dieses Modell wurden fast alle Bilder ab dem unbearbeiteten Teil einschließlich der unterschiedlichen Achsen genaustens markiert. Trotzdem zeigt der unbearbeitete Teil unzufriedenerweise noch viele "Fusseln", "Löcher" und "Unebenheiten" auf. Der Zeitaufwand war enorm und somit wurde klar, dass der Datensatz vorher gut bearbeitet sein muss, um die Arbeitszeit zu reduzieren.
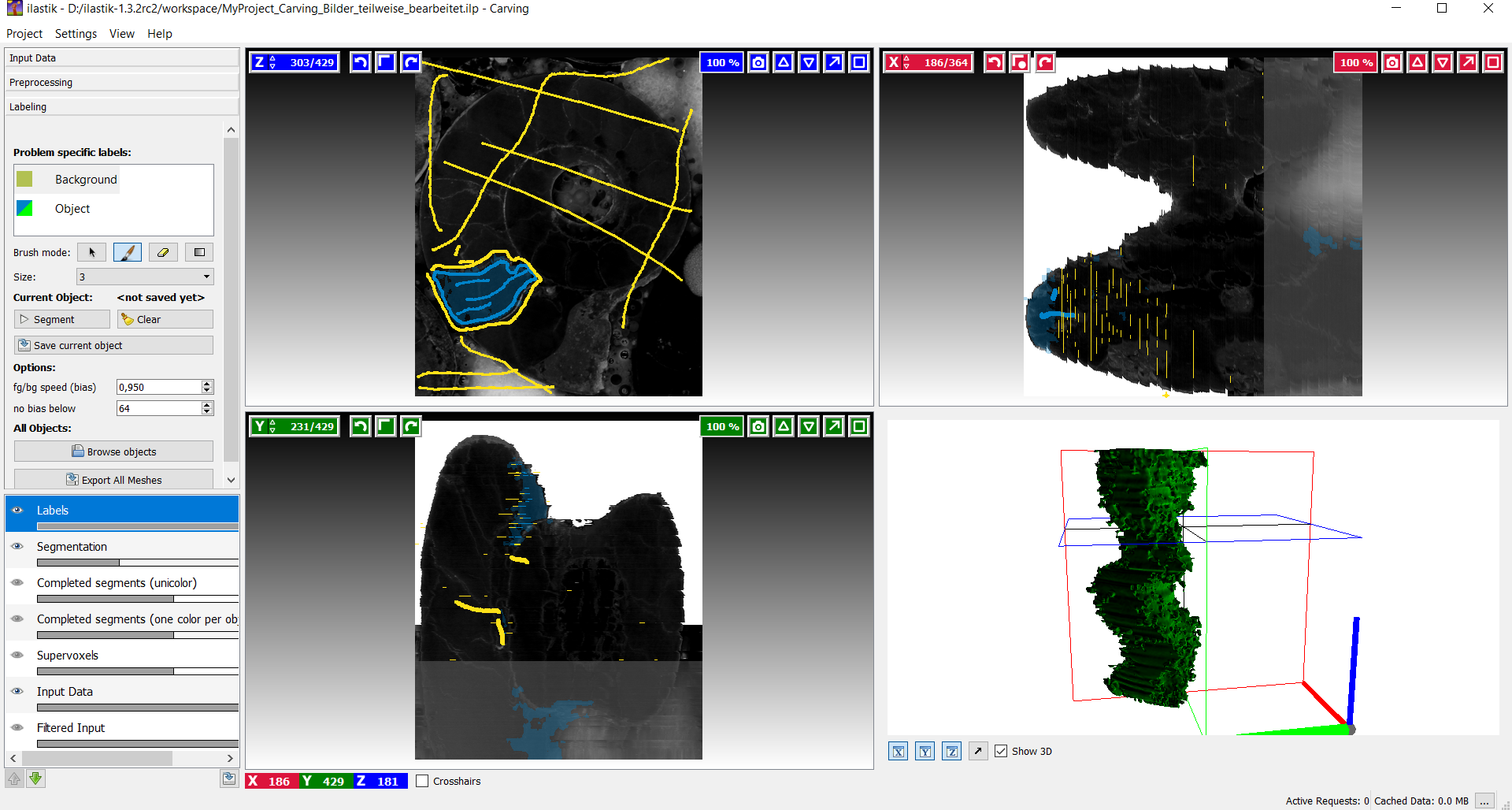
Mit vorheriger Segmentation
Die nachfolgende Bilderreihe zeigt nun das 3D Modell mit vorheriger Bearbeitung über den HSV Farbraum. Ohne großen Aufwand beim Labeling (< 5 Bilder), erhält man nun ein viel besseres Ergebnis.
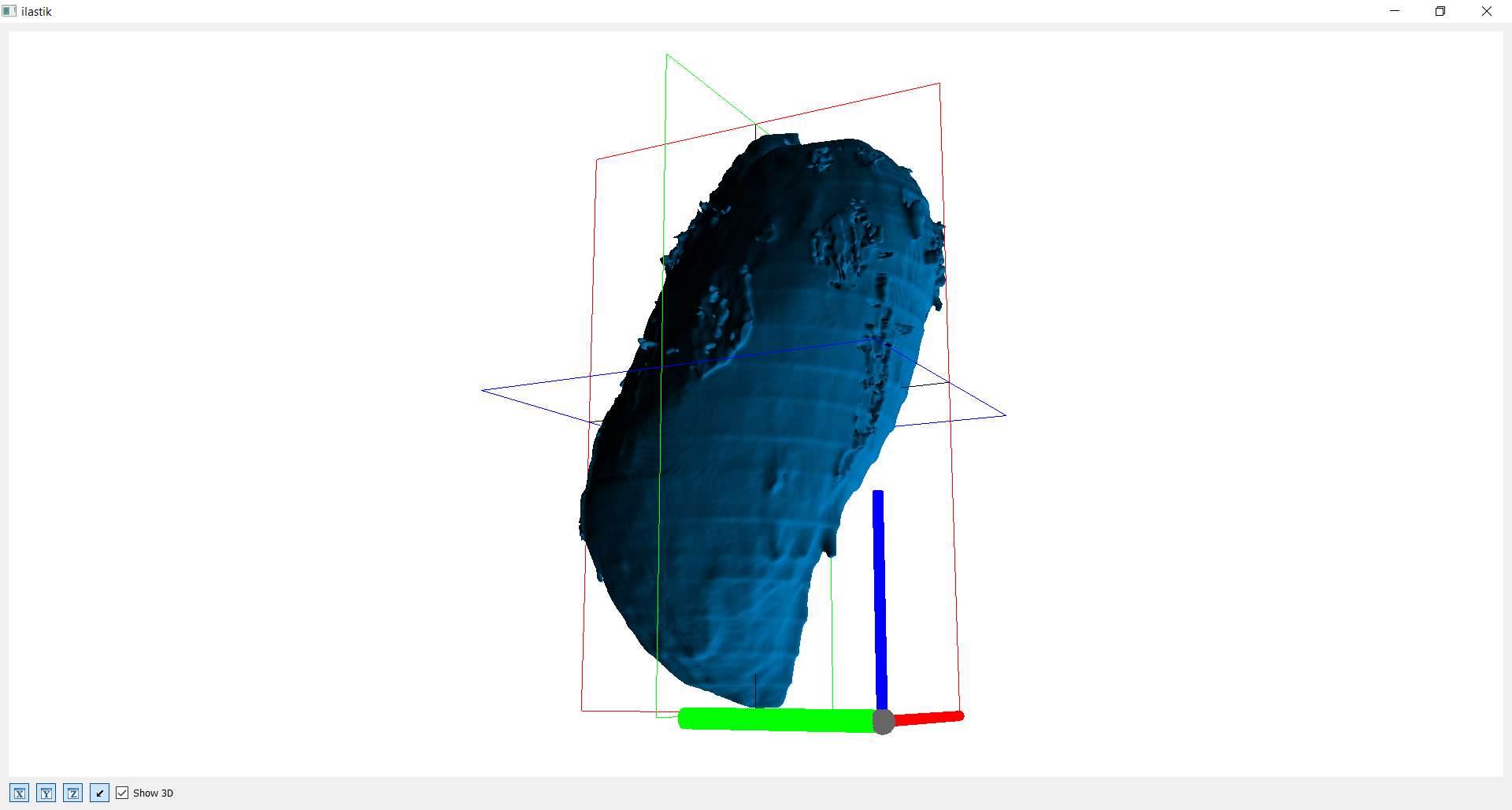
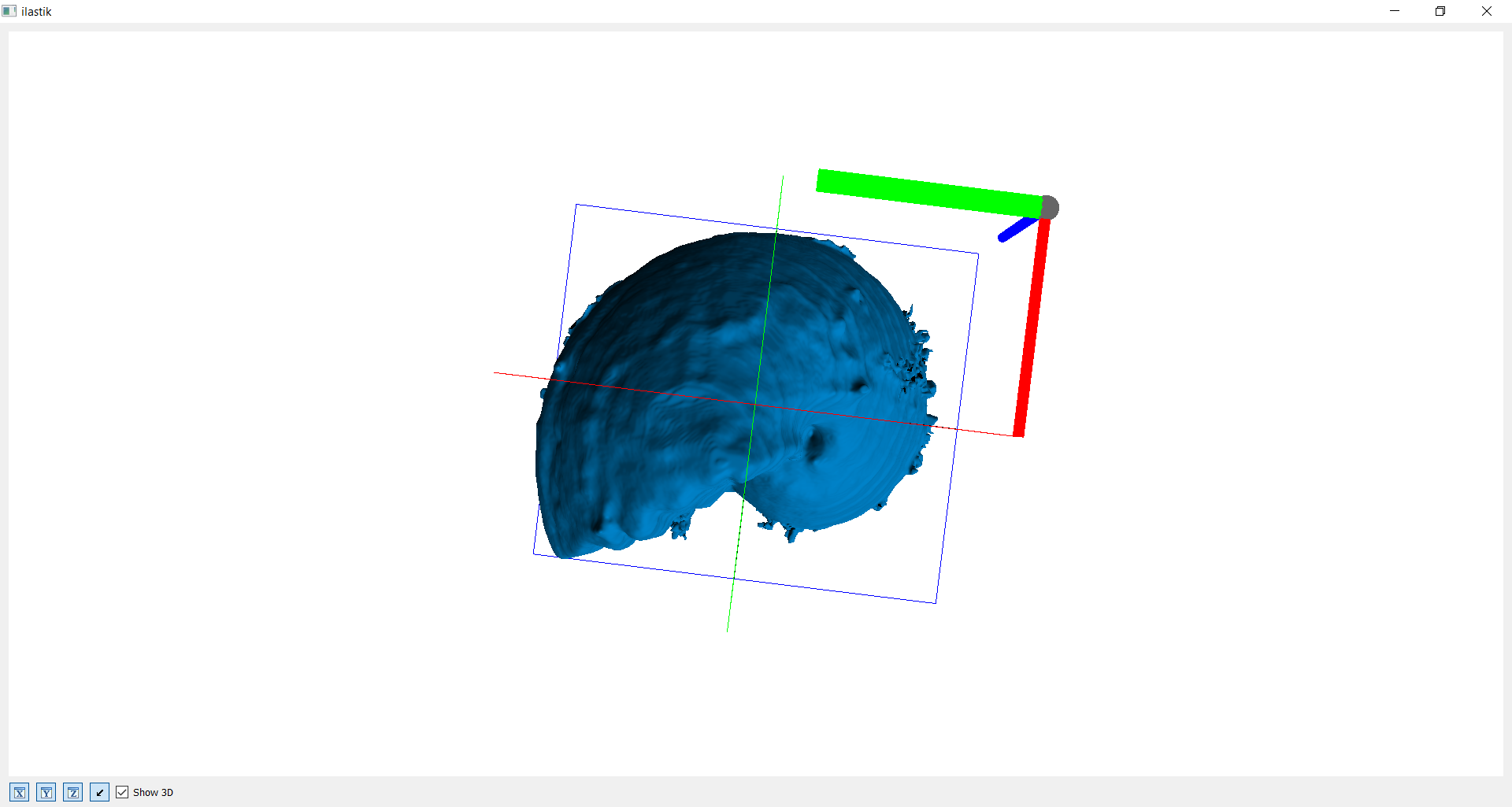
Hat der Benutzer einmal ein Objekt erfolgreich segmentiert, dann kann das Ergebnis hinterlegt werden, indem man den „save“ Button betätigt. Es poppt ein Dialog auf mit der Frage nach dem Objektnamen. Nach dem Sichern eines Objekts, werden alle bestehenden Markierungen aufgehoben und erlauben somit die Segmentierung eines neuen Objekts. Um zu sehen, welche Objekte bereits segmentiert und gespeichert wurden, kann durch klicken des Augen Icons in diesem Layer das vollständig segmentierte Overlay hinzugefügt werden.
Hervorhebung eines Teilobjekts
Nachdem das aktuelle Objekt über “save current object” gespeichert wurde, kann nun das Labeling auf das Teilobjekt beginnen. Es sollte darauf geachtet werden andere Farben zu verwenden, damit das Teilobjekt in der Gesamtansicht auch wirklich hervorgehoben wird.
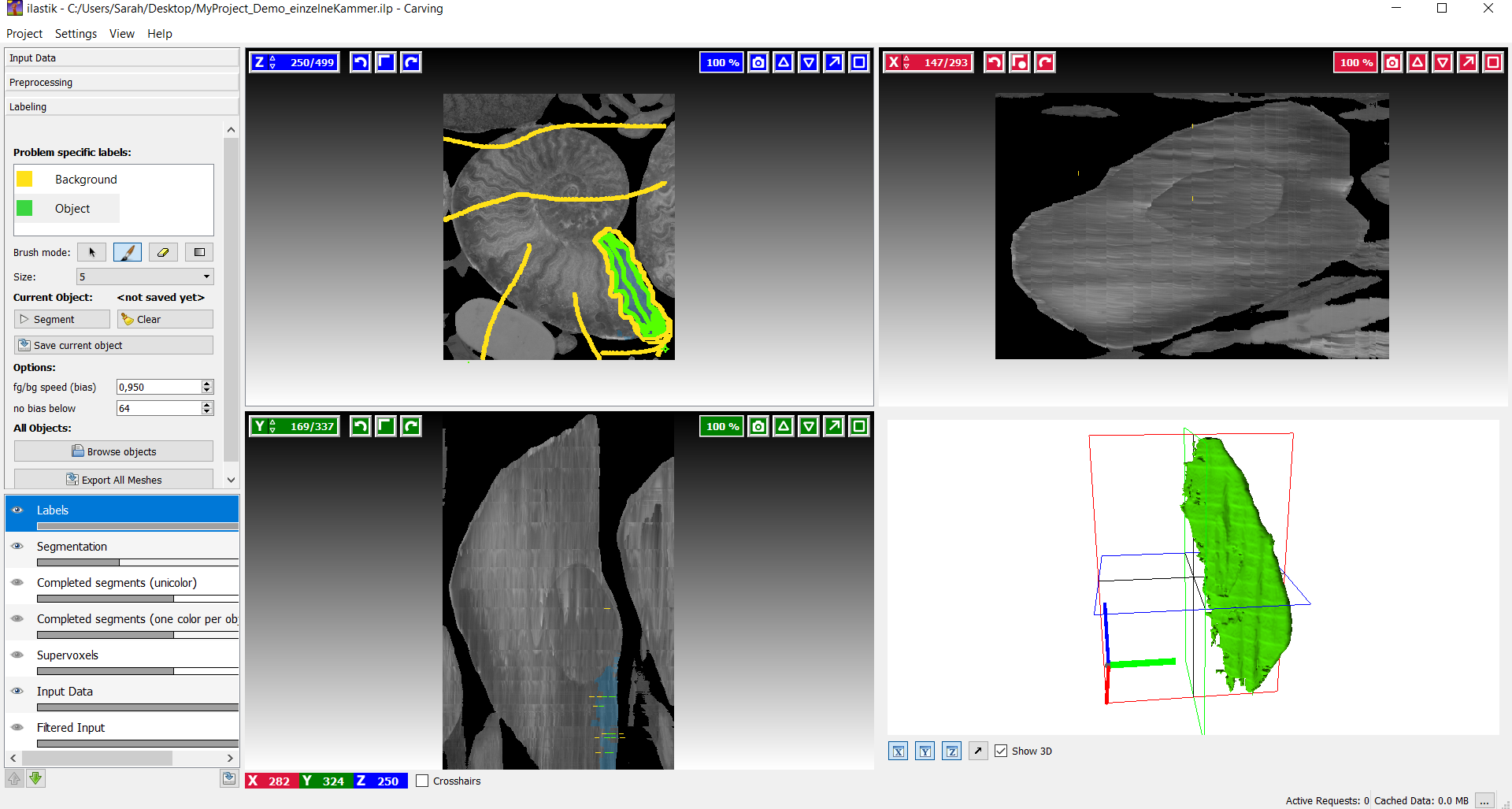
Einzelne Kammer
Dieses Bild zeigt eine einzelne Kammer ohne Vorbearbeitung des Datensatzes. Obwohl beim Labeln sehr viele Bilder ziemlich genau markiert wurden, wies das Ergebnis viele Artefakte und Unebenheiten auf.
Hier wiederum erkennt man durch die Vorbearbeitung eine Verbesserung zum vorherigen Bild. Das Ergebnis ist noch nicht perfekt, weist auch noch Mängel auf, aber der Aufwand ist schon um einiges niedriger. Es wurden nicht mehr als 5 Bilder des Datensatzes gelabelt. Die Herausforderung im Allgemeinen liegt noch darin, eine Möglichkeit zu finden, die Segmentierung einer einzelnen Kammer zu verbessern, ohne den kompletten Rand des Objekts nachzeichnen zu müssen.
Kombination aus einzelner Kammer und Hülle
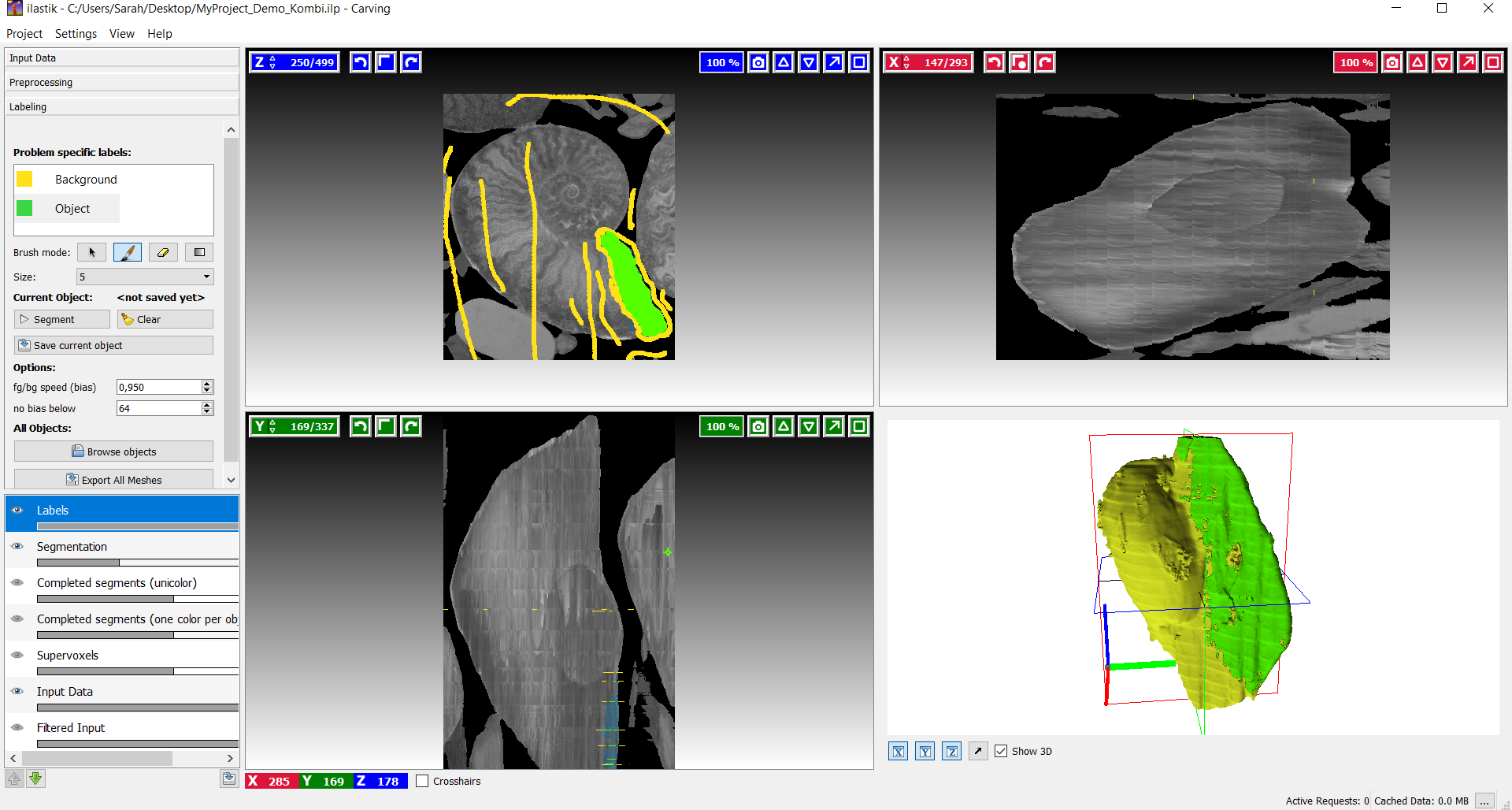
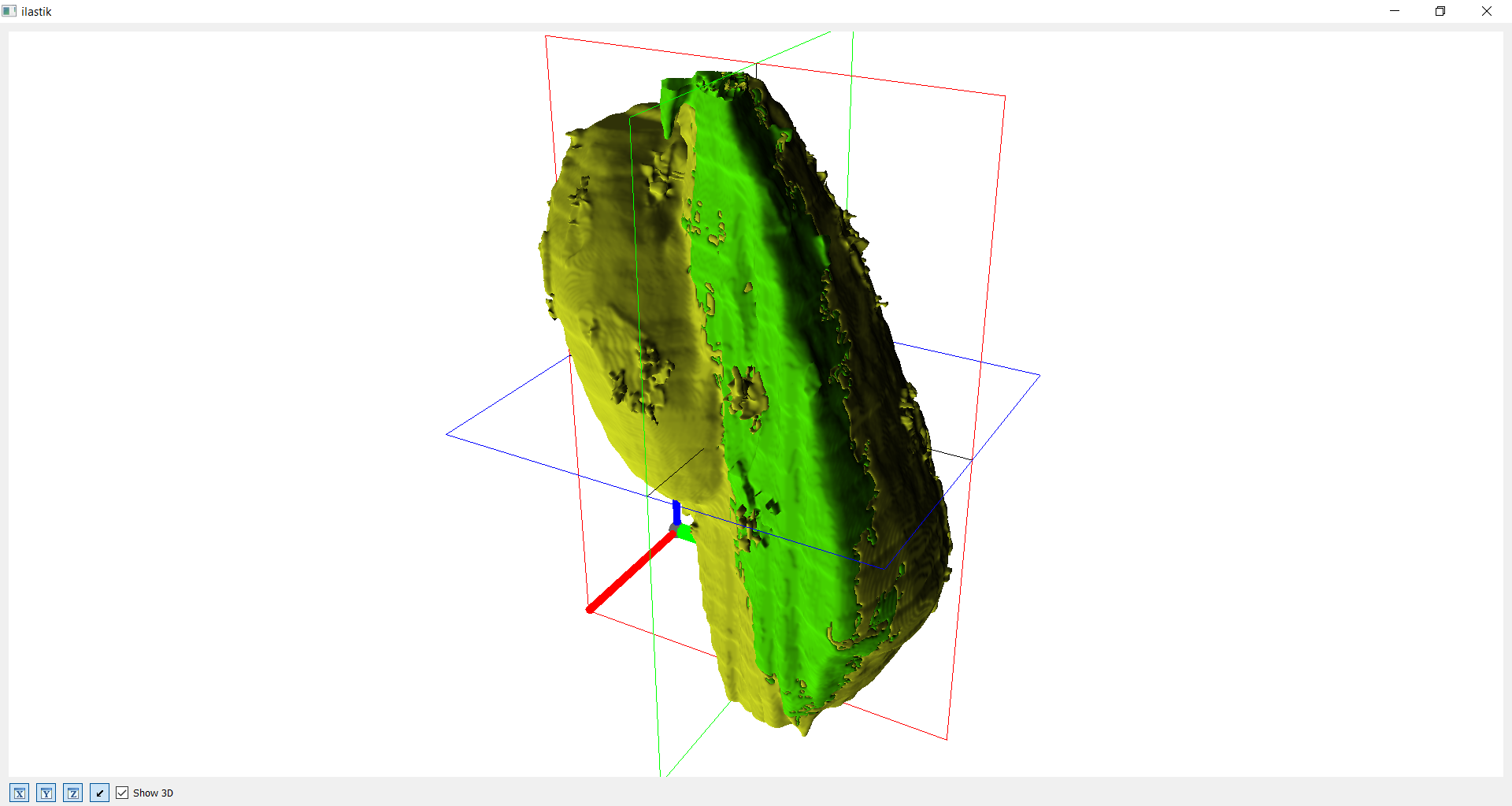
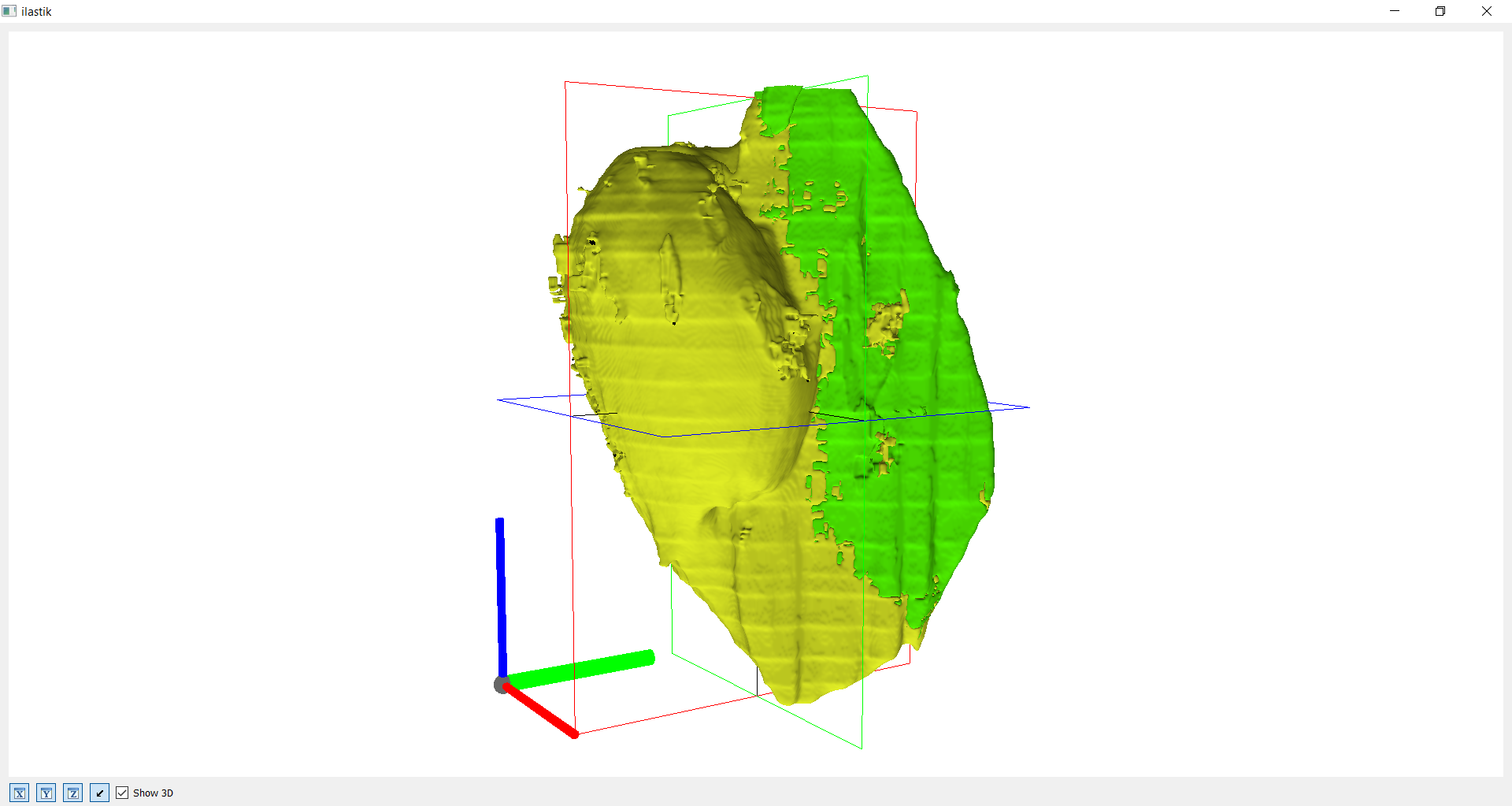
Auf diesen Bildern wird die Gesamtansicht, also die Kombination aus der einzelnen Kammer und des gesamten Fossils, dargestellt. In der Gesamtansicht fallen die Defizite der Segmentation eindeutig auf. Daher besteht auf jeden Fall noch verbesserungsbedarf.
Export in Ilastik
Die einzelnen Objekte lassen sich als OBJ-Dateien exportieren. Dies ermöglicht einen Import in funktionsreichere 3D-Programme wie z.B. meshlab. Ein wichtiges Feature, da die Daten nicht an ilastik gebunden sind, sondern für die Weiterverarbeitung und Darstellung auch an andere Institutionen weiter gereicht werden können, die mit unterschiedlicher Software arbeiten.
Übertragung des 3D Objekts in Meshlab
Meshlab is an open source system for processing and editing 3D triangular meshes.
It provides a set of tools for editing, cleaning, healing, inspecting, rendering, texturing and converting meshes.
It offers features for processing raw data produced by 3D digitization tools/devices and for preparing models for 3D printing.
[4]
Surya in meshlab
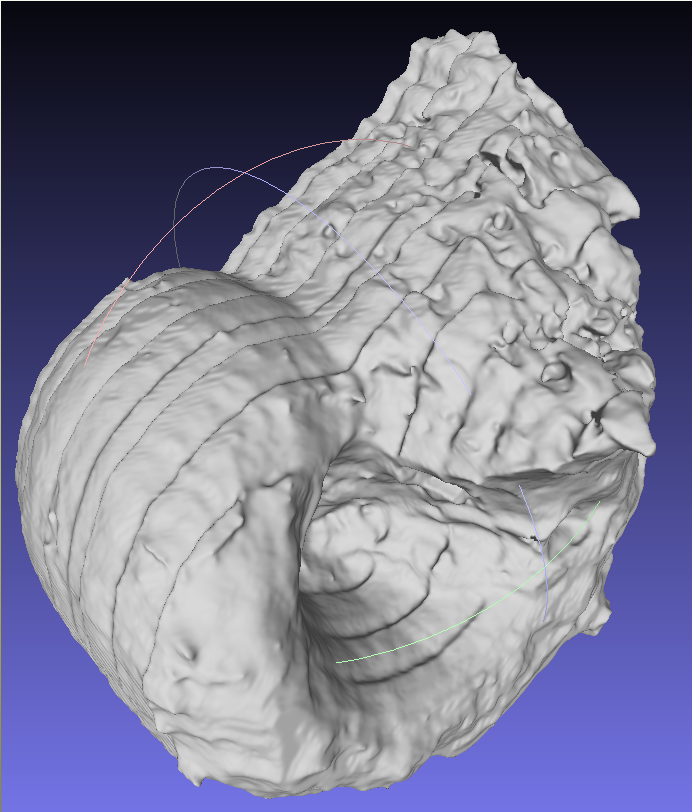
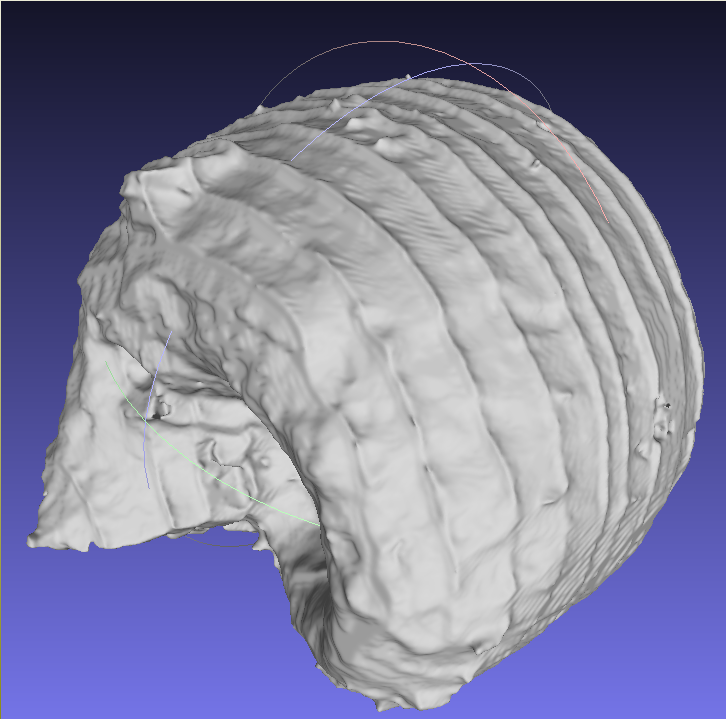
Lobatus in meshlab

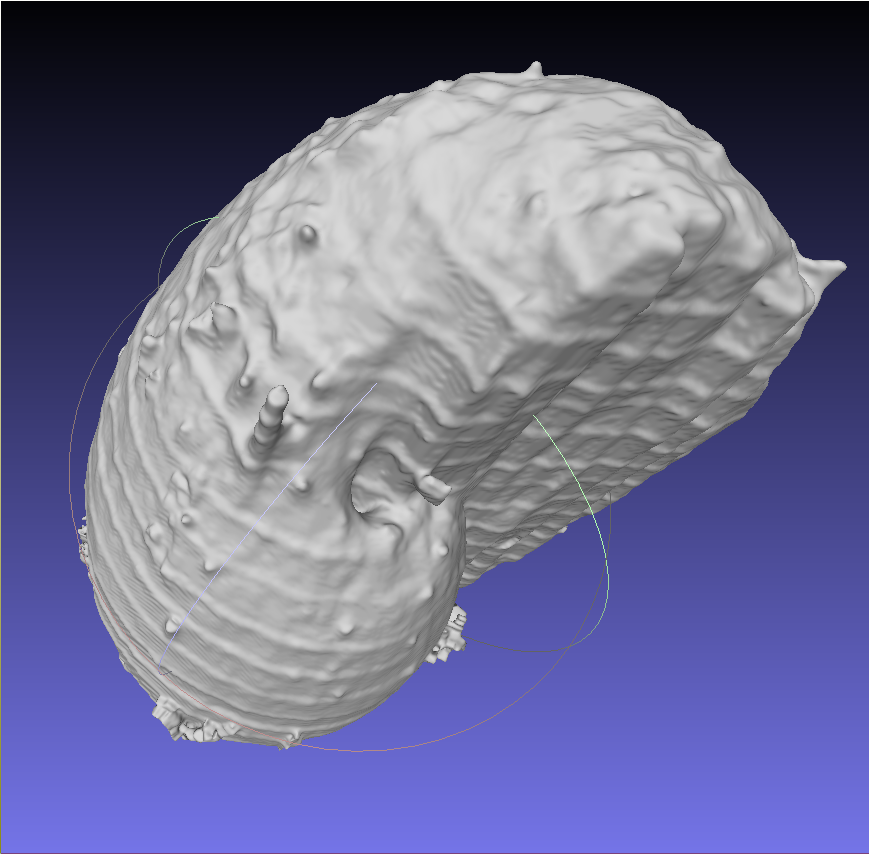
Workflow
Bestmöglich ausgearbeiteter Workflow
- Preprocessing der Bilder durch folgende Pythonskripte:
scale.py & filterByColorSpace.py & convert2grayscale.pyDurch den nachfolgenden Befehl werden alle notwendigen Skripte ausgeführt.
python main.py --src="data/Slobatus" --dest="results/Slobatus" --scale=0.5 - Neues Carving Projekt in ilastik erstellen und Datensatz importieren
- Labeling Vorder-/Hintergrund
- 3D Modell anzeigen und speichern
- 3D Modell sukzessiv durch labeling (versch. Farben) einzelner Kammern erweitern
- Alle Objekte anzeigen, speichern und exportieren
- In gewünschtem 3D Programm importieren
Ausblick
Bisher konnte mit Hilfe von Pythonskripten und Carving in Ilastik ein erstes 3D Modell relativ schnell erzeugt werden. Allerdings ist das Ergebnis noch verbesserungswürdig. Die Oberfläche weist noch zuviele Artefakte und auch viele Unebenheiten bzw. Rillen auf. Somit besteht ein weiteres Ziel darin dies zu optimieren. Der Inhalt des Objekts sollte ebenfalls präziser dargestellt werden. Es fehlen zuviele Details, die für die Fossilien Analyse interessant wären. Schließlich möchte man möglichst viel über die Morphologie bezüglich des inneren Aufbaus in Erfahrung bringen. Zudem hat man sich innerhalb des Praktikums bereits mit der Farbtheorie auseinandergesetzt und auch erfolgreich ausgenutzt. Dies gilt es jetzt zu erweitern und zu verfeinern. Dadurch könnten alle weiteren Prozesse um ein vielfaches vereinfacht werden. Abgesehen von den hoch priorisierten Aufgaben, wäre ein weiterer möglicher Schritt am Automatismus des Ablaufs zu arbeiten, sodass die Benutzer ohne Probleme und ohne aufwändige Einarbeitung ihre Arbeiten durchführen können. Darunter gehört unter anderem auch die Anzahl der verwendeten Programme zu reduzieren.
Fazit
Abschließend zum Praktikum lässt sich nun zusammenfassend sagen, dass die Ersparnis des Arbeitsaufwands durch 'Preprocessing', also vorheriger Segmentierung insbesondere über den HSV Farbraum, enorm ist. Mit den verfassten Python Programmen und Carving in Ilastik ist es nun möglich ein einfaches 3D Modell zu erzeugen, welches als .obj Datei gespeichert und exportiert werden kann. Dadurch lässt es sich problemlos auf andere Programme übertragen. Es besteht also keine Gefahr, dass die Ergebnisse bei Verlust oder Veralterung von Ilastik verloren gehen. Zusätzlich gibt es einem die Möglichkeit das Objekt in einem ausgereifteren Programm zu verbessern. Die Segmentation einzelner Kammern zum Beispiel ist über Ilastik ebenfalls möglich, aber weder trivial noch detailreich.
Über uns
Sarah Fenrich
Studiengang: BSc Angewandte Informatik
Email Adresse: fenrich@stud.uni-heidelberg.de
Marian Röhling B.Sc. Angewandte Informatik