Photogrammetry using Stereo Image Pairs
print("Welcome to our Project Page")>>>"Welcome to our Project Page"
Hello and welcome to our website. We are Justin Sostmann and Manuel Trageser and we are both studying Applied Computer Science. This project was supervised by Susanne Krömker as part of our computer graphics beginners practical. On this site you will find descriptions and explanations of the algorithms we used for this practical as well as a link to an interactive python web application to experiment on your own.
Check this project out on GitHub. Or see our presentation (german).
What is Photogrammetry?
Photogrammetry is the science of making measurements from photographs. It is used to reconstruct the third dimension (the depth) of two-dimensional images. The application of photogrammetry is widespread and includes surveying, measuring, modeling, and 3D reconstruction.
Related fields
- land surveying
- google earth
- computer vision
- autonomous driving
- computer graphics
- 3D modeling
Approaches
- Shape from Shading
- reconstruct the shape of an object using shadow and light information
- Structure from Motion
- reconstruct the 3D structure of a scene from a set of 2D images
- Stereo-photogrammetry (our approach)
- keypoint triangulation
Motivation
In the past we worked on a video game. One of the main challenges was to create good looking 3D models. Creating 3D models is a time consuming task. We already knew of photogrammetry as a way to automate model generation, but didn't know how it worked. Furthermore we are generally interested in computer vision and image processing. So we decided to learn more about it and create our own photogrammetry project.
Goals
- learn about camera basics
- 3D to 2D projection
- learn about image processing
- implement in python
- generate meshes in python
- different mesh formats
➤ generate 3D-model from images
Theory
In its simplest form an image is the projection of a 3D scene onto a 2D plane. This projection can be illustrated by the pinhole camera model.
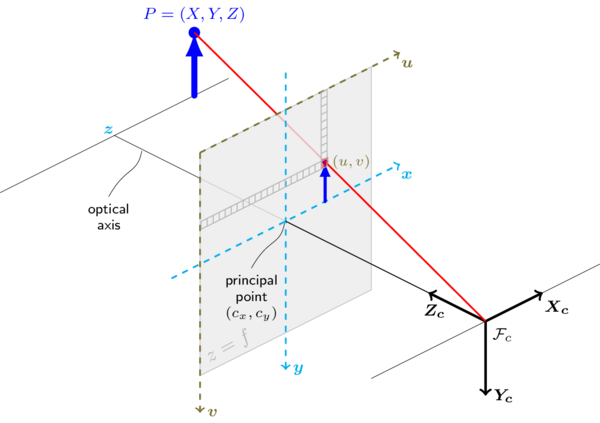
Such a projection can be described by the following equation:

To get back to the 3D coordinates we need to invert the equation. This is not fully possible from a single image, but we can get a good approximation by using multiple images. For this we need to know the position of the camera in the 3D scene. Furthermore we assume that our cameras are perfectly coplanar, this means that the epipolar lines are perfectly horizontal.
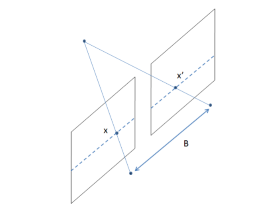
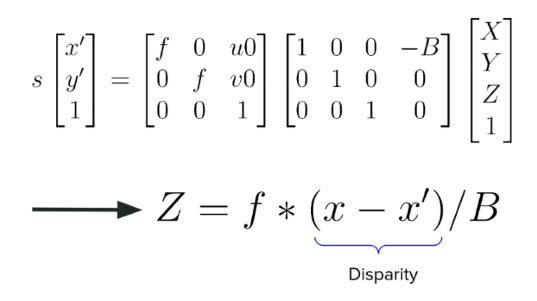
By exploiting the epipolar geometry we can triangulate the 3D coordinates of a point from two images.
Practice
Used modules
- Dash
- website
- OpenCV
- general image library
- Open3D
- meshes and point clouds
- Plotly
- plot results
To familiarize ourself with the previously listed Python libraries we first worked on two smaller algorithms, image background segmentation and litophane generation. These two algorithms are not directly related to our final photogrammetry process, but they helped us to get a better understanding of image processing and mesh generation. Afterwards we started working on our Stereo Photogrammetry approach.
Segmentation
Separate the main object of an image from the image background
Algorithm
- remove dark noise by increasing brightness in HSV format
- conversion to grayscale
- use of a fixed threshold to create a mask (make all grayscale values higher than x completely black and all others white)
- use openCV to smooth the edges of the mask and to remove noise
- find the largest contour in the mask (since this is the one most probable to cover the wanted object) --> remove all other contours
- apply mask to image
Results
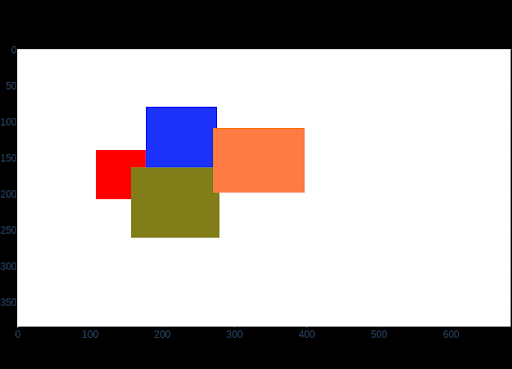
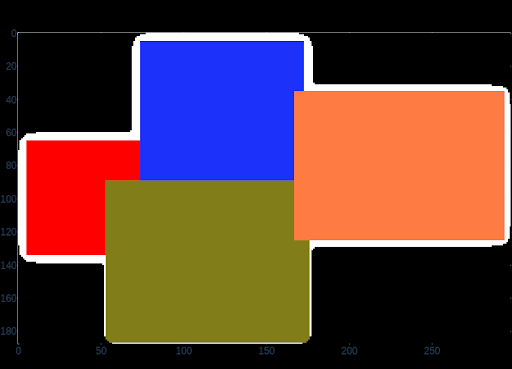
Litophane
Litophane is an old technique. It uses a plate with engraved contours. When light passes through the plate parts with thicker contours are darker (since less light can pass). Our application turns this approach around. We assume that darker spots of an image are located in the front of the 3D scene while brighter spots are in the back.
Algorithm
- convert RGB value to grayscale (0-255)
- use the grayscale value as Z coordinate
Results


Stereo Photogrammetry
Prerequisite
Having 2 Stereo Image pairs, showing the same scene which are horizontally shifted by a certain baseline.
1. Rectification
To make it easier for the disparity map algorithm we performed a rectification on our images pairs to correct non perfect horizontal shifts. When the image pairs are perfectly shifted and therefore lie on the same plane, the epipolar lines are perfectly horizontal. This allows us to reduce the search for matching pixels to the epipolar line. To do so we used a SIFT keypoint matching algorithm by OpenCV, which finds unique points on both images and matches them (it is important to note that this keypoint matching can not be used later because the disparity map requires all pixels to be matched, while SIFT only matches unique keypoints). The resulting epipolar lines from the matched keypoints are used to transform the images so that the epipolar lines are horizontally aligned.
Results

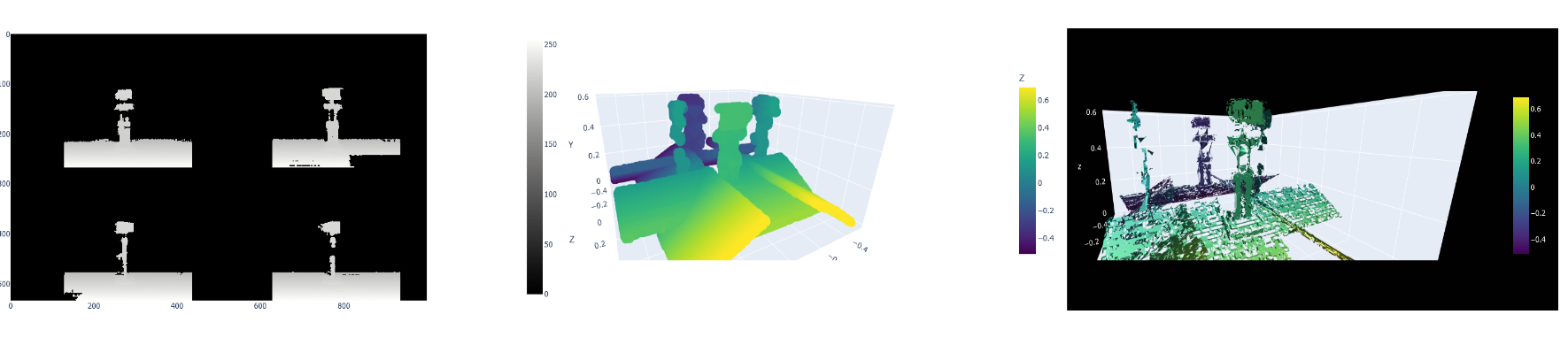
2. Disparity Map
We used the openCV StereoBSGM algorithm to perform a block/pixel matching between our rectified image pairs and to calculate the displacement vector between those blocks/pixels --> disparity map.
Problems when calculating disparity map
- pixel/block matching requires patterns
- it is impossible to match pixels between the images if every pixel has the same color
- baseline shift between image pairs needs to be chosen so that an parallax effect can be seen
- requires good depth of field
- if the depth of field is too small too much noise is introduced
Results

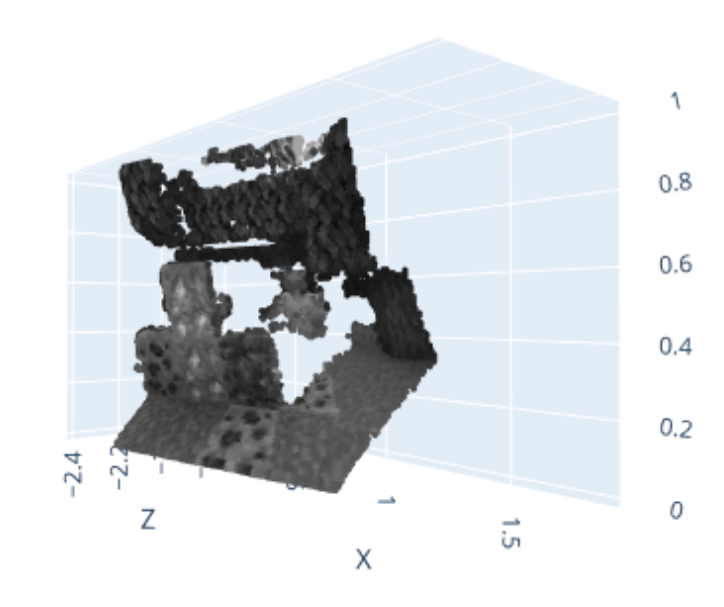
3. Stereo Point Cloud
The depth of each pixel is calculated by multiplying the disparity value with the baseline and the focal
length.
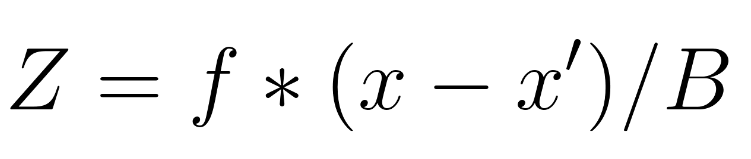
Results
3D Model / Mesh
To create a full 3D Mesh out of our Point clouds we need to calculate such a point cloud for every side of an object (object from the left, right, top etc.) Then these different Models from different perspectives need to be matched together, which we did not further study in our project, but which could probably again be done by some sort of keypoint matching.
Results