Image Preprocessing
Der erste und der wichtigste Schritt fürs Lösen des OCR-Problems beginnt mit dem Aussuchen, Sammeln und Aufbereiten der Bilderdaten. Diese Daten werden dann in der Trainings- und Testphase der neuronalen Netze eingesetzt. In der Trainingsphase wird das vorgegebene Lernmaterial vom Netz eingeübt, indem die Gewichte geändert werden. In der Testphase wird anschließend auf Grundlage der bereits modifizierten Gewichte untersucht, ob und was das Netz tatsächlich gelernt hat. Die Datensätze werden bzw. als m x n große Bilder dargestellt. Ich habe insgesamt 5 Datenmengen mit jeweils 40 handgeschriebenen chinesischen Zeichen erstellt.
Drei sind die Hauptschritte der Datenvorbereitung:
- Aussuchen der Zeichen Ausgesucht wurden Zeichen, die sich durch große Ähnlichkeit auszeichen, obwohl sie komplet unterschiedliche Bedeutungen haben. Auf diese Weise wurde das Verhalten des Netzes bei verrauschten Daten untersucht, ob die korrekte Vorhersage getroffen wird oder etwa ein ähnliches Zeichen erkannt wird.
- Vorbereiten der Bilddaten
- Eliminierung vom Hintergrundrauschen
- Umwandlung in binäre Bilder
- Normierung der Bildgröße - 1024 x 1024 Pixel
- Finden von bounding boxes
- Skalierung der bounding boxes - 64 x 64 Pixel
- Definieren der Ein- und Ausgabe
- Eingabe - 4096 x 40 Vektor Alle 64 x 64 Pixel des jeweiligen Zeichens werden "resized" und durch ein 4096 x 1 Vektor dargestellt.
- Ausgabe - 40 x 40 Vektor Der Ausgabevektor besteht aus Nullen und Einzen, wobei 1 an der bestimmten Position steht, die das gegebene Zeichen im neuronalen Netz darstellen soll.


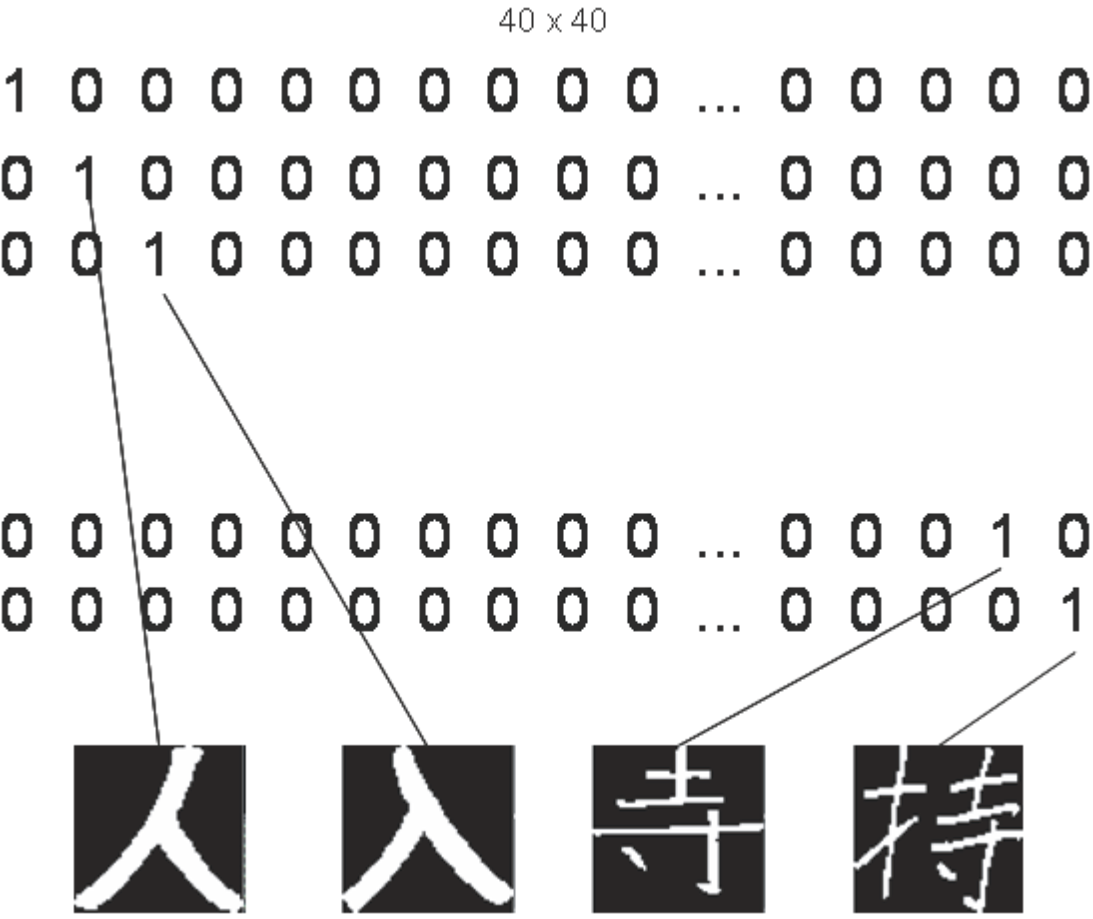
Die Ausgabe ist nicht das eigentliche Zeichen, sondern nur ein Verweis auf das Schriftzeichen.